10 Eyewitness Testimony
10.1 Introduction
Courts rely on eyewitness evidence in many criminal cases. When a witness identifies a suspect at a lineup, or describes events they observed, that account carries weight with investigators, prosecutors, and judges. The factual accuracy of such accounts is treated in many jurisdictions as a matter for the court to assess on the basis of ordinary experience. The scientific record, however, shows that ordinary experience is a poor guide to the reliability of eyewitness evidence.
Error is the subject of this chapter, and the central lesson from decades of research is that eyewitness error is not random. It is systematic and predictable. It arises from the conditions under which crimes are witnessed, from the passage of time between event and identification, and from the procedures investigators use to gather evidence. Because these sources of error are identifiable, many of them are also preventable.
This chapter surveys the science of eyewitness testimony for an applied cognitive psychology audience. It draws on international research that establishes the mechanisms of eyewitness error, and on South African research that contextualises those mechanisms for local legal and operational conditions. The two bodies of work address partly different questions. They are most useful when read together.
The chapter proceeds as follows. The scale of the error problem is covered first, drawing on wrongful conviction data and confidence inflation studies. A conceptual framework for organising the variables follows. are then reviewed; that is, properties of the witness, the crime, and the perpetrator that affect accuracy but cannot be controlled after the fact. The chapter then covers memory for persons more broadly, including verbal descriptions and composite images. A dedicated section addresses post-event contamination, which can alter memory without the witness or investigator being aware. The chapter then turns to ; among other things, this includes interviewing procedures and identification procedures. Confidence and accuracy, expert testimony, and the South African legal context each receive separate treatment, followed by coverage of special populations and emerging technology.
10.2 The Scale of the Error Problem
The most direct evidence that eyewitness errors occur in real cases comes from wrongful conviction research. Garrett (2011) examined 250 DNA exonerations in the United States and found that 76% involved a mistaken eyewitness identification. In 36% of those cases, more than one witness had independently made the same error. These figures are not an artefact of unusually weak cases. Many of the convictions involved witnesses who were confident, and therefore persuasive, at trial.
The exoneration record understates the true rate of eyewitness error. DNA testing can be deployed in fewer than 10% of criminal cases, predominantly serious violent offences where biological material was preserved. Cases resolved by guilty plea (common in the USA), and cases without preserved biological evidence, cannot be reopened in the same way. The exoneration datasets thus capture only the errors that became visible under specific evidentiary conditions.
The Innocence Project currently reports 375 DNA exonerations, with figures stated as current to 11 February 2026 (Innocence Project, 2026). Innocence organisations in Canada, the United Kingdom, Australia, and elsewhere have developed related initiatives. In South Africa, a formal wrongful-conviction registry does not yet exist, but work has begun to document relevant cases (see Espag’s MA thesis on this topic, at UCT). One frequently discussed South African case is that of the so-called “Eikenhof Three,” in which three men spent approximately five years in prison for murders they did not commit (Tredoux & Chiroro, 2005).

In many of the exoneration cases examined by Garrett (2011) confidence inflation was an important factor. Garrett’s analysis of the DNA exoneration cases suggests that one of the factors at play was that witness confidence at trial often did not match the confidence expressed at the initial identification. Witnesses who were initially uncertain later testified with great certainty. Garrett linked this pattern to suggestive identification procedures and other forms of contamination, while the broader eyewitness literature indicates that confirming feedback, repeated exposure to the suspect, and the inherently suggestive dynamics of pretrial and courtroom settings can all contribute to later confidence inflation.
Another notable characteristic of false convictions based on eyewitness evidence is that cross-racial misidentification is overrepresented. This pattern is consistent with an extensive laboratory literature showing that recognition accuracy is lower for faces from groups other than the observer’s own (J. K. Lee & Penrod, 2022; Meissner & Brigham, 2001; Sporer, 2001).
It would be incorrect to say that the problems of mistaken identification have not been recognised or treated carefully by legal systems around the world. South African courts, for instance, have recognised the risk of mistaken identification for over a century and have developed cautionary rules accordingly. In South Africa, section 37(1)(b) of the Criminal Procedure Act 51 of 1977 provides the statutory basis for making suspects available for identification, while much of the detailed procedure is governed by police instructions and case law (Tredoux et al., 2024). This legal caution is necessary but insufficient. If the identification procedure was unfair, if the witness was contaminated before the lineup, or if confidence was inflated through investigator feedback, judicial caution operates on already-compromised material (Tredoux et al., 2024). The quality of evidence at court is determined before the court sees it.
The modern DNA era sharpened this lesson, but did not originate it. Long before forensic DNA, appellate courts and commissions repeatedly warned that sincere eyewitnesses could be mistaken.
10.3 A Framework for Analysis
10.3.1 Estimator and system variables
Wells (1978) distinguished two categories of variables that affect eyewitness accuracy. are features of the crime, the witness, or the perpetrator that the justice system cannot control after the fact: distance, lighting, duration of observation, witness stress, the presence of a weapon, and whether the witness and perpetrator share racial group membership. These can be estimated retrospectively but not changed. are aspects of evidence collection over which the justice system has direct control: these include how witnesses are interviewed, how lineups are constructed, what instructions witnesses receive, and whether the administrator knows the suspect’s position in the lineup.1
The distinction has practical value because it directs attention toward what can be improved. Police cannot alter the lighting conditions at a past crime scene, but they can conduct a fair lineup without inadvertent cueing. Wells and colleagues have argued that the greatest gains in eyewitness evidence quality come from improving system variables (Wells et al., 2006). A competing view holds that this focus has left estimator variable research underdeveloped and that the field lacks an adequate account of how crime conditions, witness characteristics, and perpetrator properties interact to produce the full distribution of eyewitness outcomes.
10.3.2 Memory stages
A useful supplement to Wells’ framework is the three-stage model of memory: encoding, retention, and retrieval. Error can enter at any stage. A witness might encode a face poorly because of brief exposure or high stress. That memory might then be altered during the retention interval through post-event information or co-witness contact. It may ultimately be expressed inaccurately because retrieval conditions are suggestive. These stages are not equivalent, and effective procedural reform must address each of them (Tredoux et al., 2004; Tredoux & Py, 2020).
10.3.3 Discriminability and decision criterion
offers an additional conceptual tool, and is discussed in the measurement sections below. Our current understanding of memory systems is that they do not produce categorical outputs; they produce graded signals. When a witness examines a lineup member, the familiarity of that face falls somewhere on a continuum. The witness’s decision to identify or reject depends on how that familiarity signal compares against a criterion or threshold. Two witnesses may have identical memory representations but apply different criteria, producing different response patterns. Distinguishing genuine discriminability (the ability to tell target from foil faces) from criterion effects (the threshold at which a witness decides to make an identification) is essential for interpreting identification outcomes. A procedure that lowers false identification rates is only beneficial if it also preserves discriminability. If it merely raises the response threshold without improving memory, correct identifications will fall alongside false ones, and the overall informativeness of the procedure will not improve (J. Lee & Penrod, 2019; Lindsay et al., 2009; Meissner et al., 2005).
10.4 Estimator Variables
10.4.1 Viewing conditions
The quality of encoding depends on how well the witness could see the perpetrator. Distance, lighting, duration, and viewing angle each constrain what the visual system can encode. Under poor conditions, even a motivated and sincere witness may produce an unreliable identification. Crimes committed at night, at distance, or in chaotic circumstances are predictably associated with lower accuracy, but this fact does not prevent witnesses from expressing confidence in their accounts. Nyman et al. (2019) found that correct eyewitness identification declined as viewing distance increased and illumination decreased; by 20 m in starlight conditions, performance was effectively at chance level. Nyman et al. (2023) extended this work to include facial masking (hoods, sunglasses), finding that each masking element imposed further accuracy reductions, and that the effects of distance, lighting, and masking combined in a way that left witnesses markedly unreliable under conditions common in actual crimes.
A related issue arises when perpetrators alter their appearance between the crime and the lineup. A witness encodes the face as it appeared at the time of the offence. If hair colour, facial hair, or distinctive features differ at the lineup, the comparison that the witness must perform is not the one for which their memory was formed. Even an accurate memory may fail to produce a correct identification when the lineup appearance diverges from the encoded appearance. This is a consequence of appearance change, not of memory failure. Jordan et al. (2023) found that naturalistic appearance variation between encoding and test, whether from disguise elements, changed hairstyle, or grown facial hair, significantly reduced identification accuracy, and that witnesses frequently failed to signal uncertainty under these conditions.
The short exercise below illustrates this directly. You will see three faces partially obscured by a mask – study each carefully and try to identify the person. After a brief pause, the faces are revealed and named.
A common error in evaluating eyewitness accounts is treating narrative richness as evidence of accurate face memory. A witness may recall many event details, such as what was said, the sequence of actions, and the positions of people, while retaining a weak representation of the perpetrator’s face. Detail quantity and identity memory accuracy are empirically separable (Wells et al., 2006).
A further caution is that good viewing conditions do not imply high-probability identification. Even under favourable laboratory conditions, face-recognition performance remains modest. Deffenbacher et al. estimated that, on a fair six-person lineup, plausible upper-bound initial memory strength corresponds to roughly a .67 probability of a correct choice (Deffenbacher et al., 2008). Sincere mistakes are therefore expected even when a witness had a seemingly clear view.
10.4.2 Stress
Most crimes occur under conditions of elevated stress. Deffenbacher et al. (2004) synthesised findings from 27 independent tests involving over 1,700 participants and found a consistent negative effect of heightened stress on eyewitness accuracy (d = -0.31). The effect held across different operationalisations of stress and across both recall and identification outcome measures. A limitation of this meta-analysis is that the studies it synthesised typically compared only two levels of stress (high versus low) without capturing the curvilinear pattern that theory predicts. Gering et al. (2023) employed a three-level stress manipulation with a South African sample and found a nonlinear pattern: extreme stress produced greater impairment than moderate stress, and the overall picture was more variable and conditional than a single negative effect size implies.
The relationship between arousal and memory performance is indeed curvilinear. Yerkes & Dodson (1908) established in animal learning research that performance peaks at intermediate arousal levels and declines at both extremes: the inverted-U function known as the Yerkes-Dodson principle. Moderate arousal supports performance; very low or very high arousal impairs it. Crime conditions are thought to push witnesses toward the high end of the arousal scale, where encoding is impaired (Christianson, 1992).
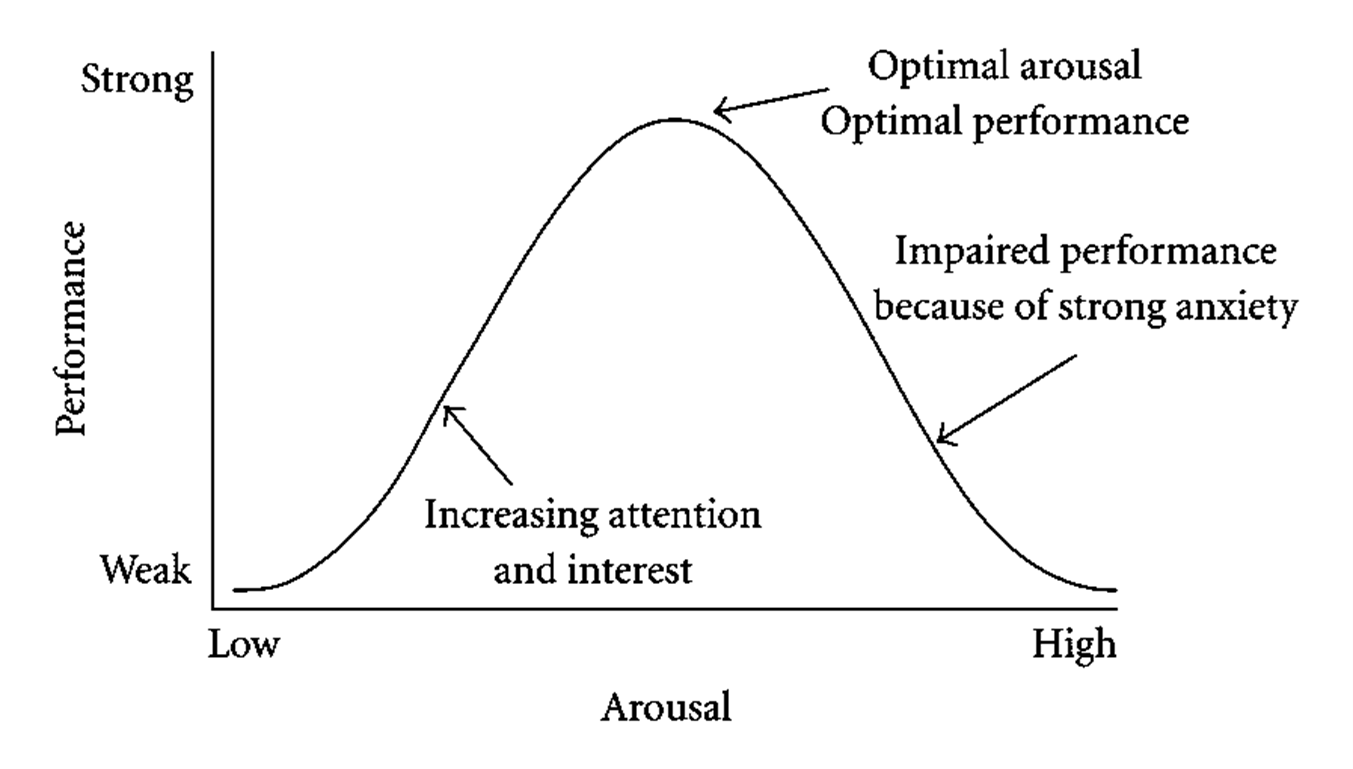
There is also a gap between expert and lay understanding of stress effects. A survey of experts and laypeople by C. Marr et al. (2021) found that lay respondents were more likely than experts to endorse memory-enhancing effects of stress in some scenarios, in line with popular ideas about sharpened perception under threat. The expert consensus, at least in the eyewitness research literature, is that extreme stress impairs face encoding. This mismatch has practical consequences: decision-makers who believe stress sharpens memory may assign more weight to stressed-witness identifications than the evidence warrants. The lay belief is not without foundation: laboratory research on stress and memory for verbal material and simple stimuli often shows neutral or even positive effects of arousal on retention. Eyewitness research, dealing with face encoding and event memory under conditions of threat or shock, produces a more consistently negative picture (C. Marr et al., 2021). The two bodies of evidence concern different tasks and different kinds of stress induction and should not be treated as interchangeable.
The literature is harder to read consistently than the Deffenbacher et al. (2004) meta-analysis alone suggests. An additional challenge is ecological validity: stress manipulations in the laboratory (e.g., threatening videos, mild physical stressors) may not reproduce the arousal levels and attentional disruption that characterise being present at a violent crime. Gering et al. (2023) highlight this problem, noting that the failure to operationalise stress as continuous and genuinely nonlinear has produced inconsistent results across studies, and that the ecological translation from laboratory stressors to real-crime conditions requires caution in both directions.
10.4.3 Weapon focus
When a weapon is visible during a crime, it draws and holds attentional resources. Fawcett et al. (2013) report a meta-analysis of the literature, with a moderate effect on identification accuracy (g = 0.53): witnesses who observed events involving a weapon were less accurate at identifying perpetrators than witnesses who observed comparable weapon-absent events.
The mechanism is contested. The threat account holds that a weapon triggers an anxiety response that orients attention toward the threat. The novelty account holds that weapons are unusual objects in most everyday contexts, and that unusual objects capture attention regardless of threat. These accounts make different empirical predictions. An unusual non-threatening object, such as a plastic chicken, should produce similar focal-object effects under the novelty account but not under the threat account. Evidence supports a role for both mechanisms, and both may operate simultaneously. Pickel (1999) provided direct evidence for the novelty account, showing that unusual but non-threatening objects produced attentional capture comparable to weapons. Subsequent work confirmed that unexpectedness is a key driver, with threat adding an independent contribution in conditions of high perceived danger (Pickel & Sneyd, 2018).
The effect appears to be somewhat stronger for recall of event details than for identification accuracy, though both are impaired. Two implications follow for evidence evaluation. First, a witness’s confident account of a weapon’s appearance does not imply comparable accuracy for the perpetrator’s face; these are distinct memory representations shaped by different attentional processes. Second, weapon presence is an estimator variable: its influence on memory occurred at the time of the crime and cannot be reversed. Procedural reform cannot undo attentional narrowing that occurred at encoding. We should also note that Kocab & Sporer (2016), in another meta-analysis of the weapon focus literature, found that the effect was reliable for recall of peripheral event details but not for face identification accuracy. This distinction matters: weapon presence may impair recall of surrounding events without comparably reducing identification accuracy.
10.4.4 Retention interval
Memory for faces deteriorates with time. Deffenbacher et al. (2008) conducted a meta-analysis of face recognition studies and found that forgetting follows a systematic function: rapid decline shortly after encoding, followed by more gradual decline thereafter. The relationship between retention interval and identification accuracy is negative and reliable. This pattern follows the forgetting function that Ebbinghaus (1885) established experimentally: memory loss is rapid in the first hours after encoding and then decelerates, producing a negatively accelerated curve that has been replicated across many domains.
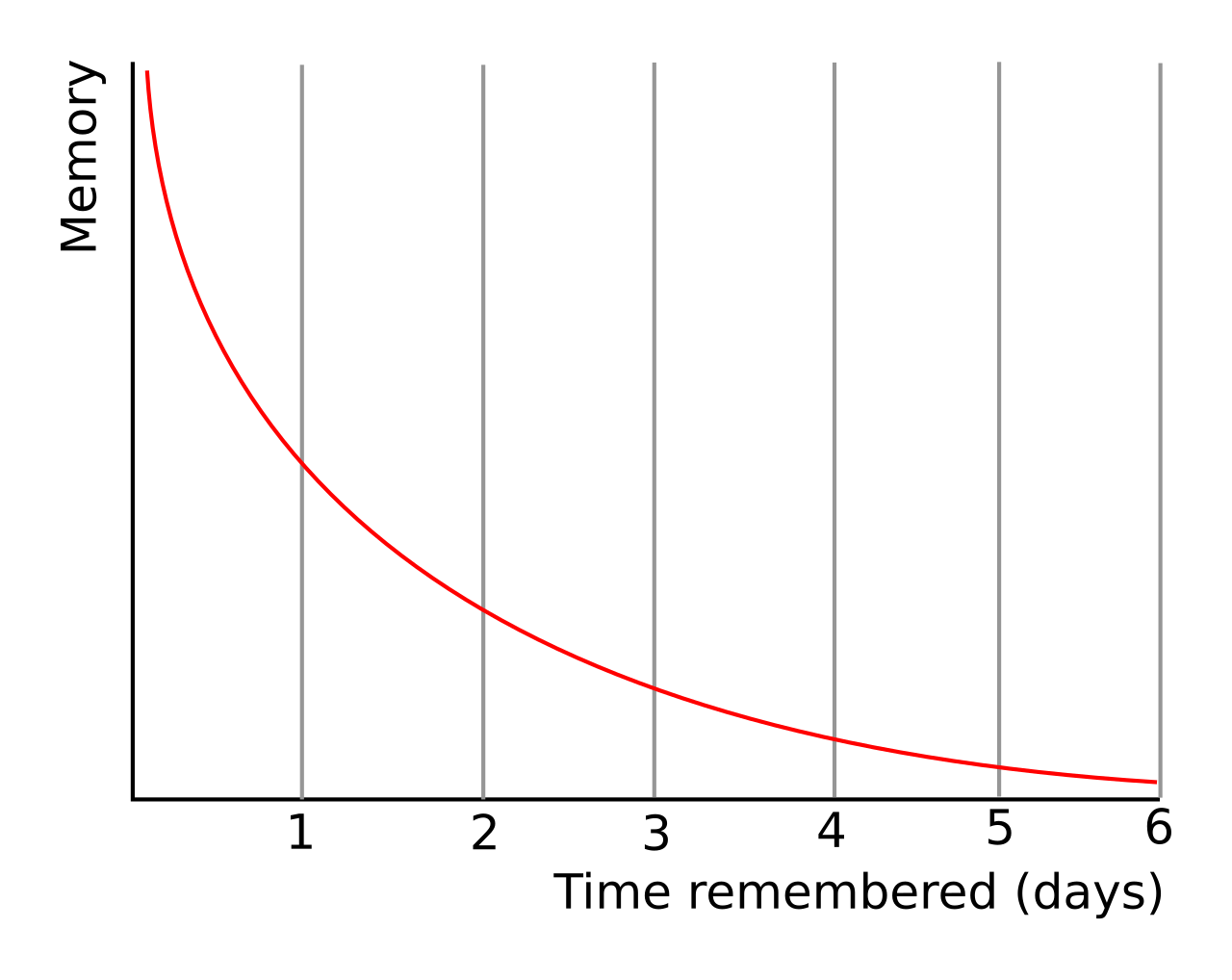
A methodological limitation of this literature is that most laboratory studies use short delays, from minutes to a few hours, and do not simulate the intervals common in actual investigations. A witness to a robbery may not attend an identification parade until weeks or months after the crime. Studies using delays in that range are relatively rare. In practice, the interval between crime and formal identification procedure in actual investigations commonly extends to weeks or months, during which forgetting continues and the risk of contamination grows. Laboratory studies using delays of minutes or hours therefore underestimate the magnitude of forgetting that real witnesses experience (Chevroulet et al., 2021; Flowe et al., 2018).
An additional gap concerns interactions across variables. Delay is usually analysed as if it operates alone, but in real cases it interacts with stress, and indeed many other factors. The field still has relatively few studies spanning the full time axis while modelling those interactions jointly, which limits direct translation from laboratory effects to the world outside the laboratory (Flowe et al., 2018).
A secondary problem is the decoupling of confidence and accuracy over time. As memory weakens, witnesses do not necessarily lower their expressed confidence, particularly when they have received confirming information or have been repeatedly exposed to the suspect’s image in the interim. An identification made weeks after a crime, following repeated suspect exposure and investigator contact, warrants different weight from one obtained within hours under so-called ‘pristine’ conditions (Wixted & Wells, 2017).
10.4.5 The own-group bias
People recognise faces from their own racial group more accurately than faces from other groups. Meissner & Brigham (2001) summarised 39 studies involving nearly 5,000 participants: own-race faces produced approximately 1.4 times higher correct identification rates and other-race faces approximately 1.56 times higher false alarm rates. The pattern constitutes a mirror effect, reflecting genuine differences in memory discriminability rather than a simple shift in response criterion. Field evidence supports the same conclusion: Brigham et al. (1982) found that store clerks correctly identified customers from another racial group in fewer than half of attempts, even within a two-hour retention interval, under conditions closely resembling real eyewitness situations. J. K. Lee & Penrod (2022), in a three-level meta-analysis of 159 studies published between 1969 and 2021, confirmed the across a wider evidence base and clarified its moderators: contact history, motivation to individuate, and social categorisation processes each contribute, with effect sizes varying substantially across conditions.
The effect affects all groups, not only White observers. Its consequences in criminal justice are not symmetric, however. Cross-racial misidentification is overrepresented in wrongful conviction datasets, in part because crimes frequently cross racial boundaries in specific social and demographic contexts. The magnitude of the own-group bias is not equal across groups. Effect sizes are consistently larger for majority-group (typically White) observers than for minority-group observers, who tend to show smaller or less reliable own-race advantages (Horry et al., 2010; Meissner & Brigham, 2001; Wittwer et al., 2019). This asymmetry means that the forensic risk from cross-race errors is not distributed equally across groups.
Two accounts of the mechanism for the own group bias in face recognition are likely complementary. The perceptual learning account holds that people develop expertise for faces they encounter frequently, internalising the features that differentiate within-group individuals. The sociocognitive account holds that categorising a face as belonging to an out-group reduces the depth of individuation: attention goes to category-level features rather than to distinctive individual characteristics (Rhodes et al., 2009). Contact quality predicts cross-race recognition better than contact quantity: meaningful intergroup relationships, rather than incidental exposure, are associated with reduced own-group biass (Brunet et al., 2022). Hugenberg et al. (2010) formalised these processes in the Categorisation-Individuation Model (CIM), proposing that categorising a face as outgroup activates a processing mode oriented toward group-level features rather than toward the individual-distinguishing features that support recognition, and that perceiver motivation and social context moderate this orientation.
A conceptual limitation is that “race” and “group” are often treated as fixed categories in experiments. This matters for external validity: effect sizes estimated under one grouping scheme may not map cleanly onto another. The itself is robust, but operational definitions and measurement choices still require greater standardisation across studies (Hugenberg et al., 2010; J. K. Lee & Penrod, 2022).
South Africa’s demography makes this effect directly relevant to local practice. Cross-race conditions do not make accurate identification impossible, but they increase error risk and cannot be fully mitigated by procedural reform alone. Cautionary instruction from courts about cross-race identification may be appropriate. South African courts have not, to our knowledge, admitted expert psychological testimony specifically on eyewitness research, though courts do apply cautionary rules to identification evidence generally (Tredoux et al., 2024).
10.4.6 Alcohol and intoxication
Intoxication at encoding affects eyewitness memory in several ways. Field studies on alcohol and cannabis suggest that intoxicated witnesses often report fewer correct details, without a corresponding increase in incorrect details, and with less consistent effects on lineup identification performance (Oorsouw et al., 2019; Vredeveldt et al., 2017). The effects therefore concern completeness more than inaccuracy.
The accuracy versus completeness distinction is diagnostically useful. An intoxicated witness may provide fewer details than a sober witness, but the details provided are not necessarily less accurate. Investigators should not dismiss a brief account wholesale on grounds of intoxication; pressing a witness for additional detail they cannot reliably provide risks introducing error. The distinction matters both for investigative decisions about evidentiary weight and for expert evaluation in court.
One methodological challenge in this literature is that experimental administration of intoxicants is ethically constrained. Studies using naturalistic intoxication face confounds of self-selection and dose uncertainty. How to study intoxicated witnesses rigorously, while respecting ethical constraints, remains an ongoing challenge for the field. Jury and police perceptions of intoxicated witnesses add a further layer of complexity: witnesses who disclose intoxication may be treated as less credible regardless of the actual accuracy of their accounts (Oorsouw et al., 2019; Vredeveldt et al., 2018).
10.4.7 Individual differences in face recognition
The previous sections concern conditions that affect most witnesses similarly. Substantial normal variation in face recognition ability also exists, independent of situational factors. Some people are notably poor at recognising faces; others are notably good. This variation is not well captured by existing identification procedures, which make no adjustment for the observer’s general face recognition ability.
At one extreme of the distribution are s: individuals whose face recognition ability is substantially above average. Police services in England have identified s among their officers and deployed them for forensic tasks such as CCTV identification. Davis et al. (2018) evaluated police super-recognisers on CCTV identification tasks and found that their accuracy substantially exceeded that of control officers, supporting the operational use of this skill for forensic applications. At the other extreme is : a severe face recognition impairment that in its developmental form is estimated to affect roughly 2% of the population. Severely impaired face recognisers may reach identification procedures without any prior assessment of their general ability.
Take the University of Greenwich super-recognition test to find out where you fall on the face recognition ability spectrum. Take the test
From the perspective of courts, the implication is that the accuracy of an identification depends partly on who the witness is. An identification from a witness with above-average face recognition ability and favourable viewing conditions provides different information from one made by an average observer under stress. Individual ability currently receives little systematic attention in evidence evaluation. A practical implication is that brief standardised face recognition tests, validated for use in research settings, could in principle be administered to witnesses before or after a lineup, generating a calibration measure that allows identifications to be interpreted with greater precision. No such routine assessment currently exists in operational practice, but the psychological tools for it do, and the conceptual case for incorporating individual-ability data into evidence evaluation is strong. The Cambridge Face Memory Test (Duchaine & Nakayama, 2006b) is one established instrument: it measures the ability to learn and recognise novel faces across changes in view and lighting, with norms extending from severe impairment to super-recognition. The Glasgow Face Matching Test and related instruments tap unfamiliar face matching, a related but distinct ability relevant to CCTV identification tasks.
Two validated instruments are freely available online. Completing both takes around 20 minutes.
Cambridge Face Memory Test – measures learning and recognition of novel faces across changes in view and lighting: Take the test
Glasgow Face Matching Test – measures unfamiliar face matching, a distinct ability relevant to CCTV identification: Take the test
10.5 Memory for Persons: Descriptions and Composite Images
10.5.1 Verbal descriptions
Before any formal identification procedure, witnesses typically provide verbal descriptions of perpetrators to police. These descriptions inform the investigation: they are used to set search parameters, screen suspects, and construct lineups. Their accuracy, and the relationship between their accuracy and later identification accuracy, is more limited than investigators typically assume.
Witness descriptions tend to be accurate for broad categorical features, such as sex, approximate age, and approximate build, but less accurate for more specific or distinctive features. The amount of detail in a description does not predict how accurate the corresponding identification will be. A witness who provides a lengthy and internally consistent description is not more likely to make a correct identification than one who provides fewer details (Wells et al., 2006).
Try the exercise below. Watch a short video of a bookshop incident, then write a description of the person you saw – then see how your description compares to the actual face.
A further problem is temporal. The verbal description obtained before the lineup establishes an account of the perpetrator’s appearance that may then prime the witness toward particular lineup members. If the description emphasises features that match one filler but not others, that description may drive selection toward the described member rather than toward the suspect. The relationship between description and lineup choice is not simple, but it is one reason why descriptions obtained immediately after an event should be recorded verbatim and preserved for later analysis. Wells et al. (2020) recommend verbatim recording of initial descriptions as a basic procedural standard, noting that descriptions provide a baseline against which the accuracy of the subsequent identification can be evaluated.
10.5.2 Verbal overshadowing
A much-researched effect in this literature concerns the consequence of describing a face before attempting to recognise it. Schooler & Engstler-Schooler (1990) showed that describing a target face in words impaired subsequent recognition of that face. This effect is thought to occur because the verbal encoding interferes with, or replaces, the holistic visual encoding that supports recognition. Faces are processed configurally rather than as collections of separate features, and verbal description is a feature-by-feature enterprise. The two representations are not fully compatible.
Meissner et al. (2001) conducted a meta-analysis of the literature and found a small-to-moderate average effect, with substantial moderation by design features such as delay and task conditions. In the multi-lab registered replication by Alogna et al. (2014), effects were variable across laboratories and smaller than in the original report.
The practical implication concerns interview sequencing. Asking a witness to describe the perpetrator in detail before a lineup identification may reduce the accuracy of that identification. This is one reason why investigative interviews should obtain a description early and thoroughly, before lineup presentation, while being aware that the description itself may have consequences for subsequent recognition. The practical weight of this finding should not be overstated. The verbal overshadowing effect is small in magnitude and, critically, appears most reliably when the description and recognition test occur in close temporal proximity (Alogna et al., 2014). At longer intervals the effect diminishes or disappears. Some researchers have argued for a verbal facilitation effect under certain conditions, where articulating features sharpens rather than impairs subsequent recognition Sporer et al. (2016). The procedural recommendation to obtain a description before lineup presentation stands, but not because verbal overshadowing is large or inevitable.
10.5.3 Composite construction
Composite face images have a long history in criminal investigation. Systems range from early feature-assembly methods (Identikit; Photo-FIT) through whole-face morphing systems (E-FIT; EFIT-V, ID) to more recent interactive systems (ID). The common aim is to produce a likeness that can aid identification of an unknown perpetrator. Tredoux, Frowd, et al. (2023) provide a historical overview of these systems and a critical review of research on their effectiveness, including coverage of AI-generated face imagery as an emerging tool for composite construction.
The UCT ID system is a modern, whole-face composite construction tool developed at the University of Cape Town. Construct a composite face at id.cogbook.org and compare the result with what you would have expected.
Research in South Africa is reported by Kempen & Tredoux (2012) Across studies, composites produced by witnesses rarely constitute accurate likenesses. Recognition of a composite by independent observers who know the target is low. Composites are better conceptualised as investigative tools, useful for alerting the public or generating suspect leads, than as evidential representations of the perpetrator’s appearance.
Construction of a composite may worsen subsequent lineup performance. The mechanism proposed is analogous to verbal overshadowing: the feature-by-feature assembly process required for composite construction may interfere with the holistic face representation that underlies lineup recognition. Sporer et al. (2020) conducted a systematic review and meta-analysis of this literature and found some, limited support for a composite-construction impairment effect on subsequent identification, the effect varying with composite system and procedure type. However, Tredoux et al. (2021) conducted a more narrowly focused meta-analysis and found that weighted mean effect sizes across the key outcome categories were not significantly different from zero. The evidence for a reliable impairment effect is therefore equivocal. The frequently given recommendation that lineup identification should precede composite construction rests on a weaker empirical foundation than is often claimed in practitioner guidance.
Beyond the sequencing question, substantial effort has gone into developing and evaluating composite systems themselves. Early feature-based systems (Identikit; Photo-FIT) were superseded by morphable systems (E-FIT; EvoFIT, ID) that allow witnesses to work with whole-face images rather than individual features. Research suggests that systems permitting holistic face processing during construction tend to produce more recognisable composites (Tredoux, Frowd, et al., 2023). More recently, AI-generated face imagery has been explored as a means of producing filler images and composite likenesses, though systematic evaluation of AI-generated composites is still at an early stage.
Return to the UCT ID programme at id.cogbook.org and explore the AI-assisted features. These use generative face models to refine composite likenesses. How does AI assistance change the process, and the result?
Performance has improved in newer systems, but remains limited. Even with modern whole-face systems, recognition rates remain variable and generally too low to justify treating composites as reliable stand-alone identification evidence (Tredoux, Frowd, et al., 2023).
10.6 Post-Event Contamination
10.6.1 The misinformation effect
Memory is reconstructive (Bartlett, 1932). Information encountered after an event can be integrated into the memory representation of that event, altering what the witness subsequently reports. Loftus et al. (1978) demonstrated this in a series of experiments: participants who were exposed to misleading verbal information about a scene they had previously observed subsequently reported memories that incorporated the misinformation. A witness who saw a yield sign might, after reading a description that mentioned a stop sign, report having seen a stop sign. The original perceptual memory was not simply supplemented; it was, at least in terms of accessible output, replaced.
One proposed mechanism is failure. Witnesses retain memories from multiple sources, including their direct observation, things they were told subsequently, things they read, and things they inferred. When these sources are not clearly tagged at retrieval, information from one source can be attributed to another. A fact learned from a co-witness or from a media report may be recalled as personal observation. M. K. Johnson & Raye (1981) described this process theoretically: people monitor the origins of their memories imperfectly, and when two sources share attributes (both are vivid, plausible, or emotionally consistent), the boundaries between them become permeable.
Striking demonstrations of this principle involve the creation of entirely false memories for plausible events. Participants in studies using photographs or narratives about childhood events have been induced to remember events that never occurred, such as being lost in a shopping mall or taking a hot air balloon ride. These studies demonstrate that the constructive nature of memory makes it vulnerable to incorporation of post-event information well beyond the correction of peripheral details. Loftus & Pickrell (1995) induced participants to believe they had been lost in a shopping mall as children by presenting a false narrative attributed to a family member; many subsequently reported detailed memories of the event. Garry et al. (1996) showed that merely imagining a childhood event, without any narrative suggestion, inflated confidence that the event had occurred, a phenomenon termed imagination inflation. Wade et al. (2002) used digitally altered photographs to induce false memories of specific events, including a hot air balloon ride, demonstrating that plausible visual ‘evidence’ can generate detailed false recollections.
The exercise below lets you experience this effect first-hand. You will watch a short clip of a traffic incident and then answer one question about it – the same clip, but with a small change in wording that affects what people remember.
This vulnerability should not be framed as total memory fragility. Across paradigms, post-event suggestion tends to distort peripheral and detail-level information more reliably than central gist. Several extensions of the misinformation framework, including verbal overshadowing and composite-related contamination, show small or inconsistent effects under many conditions (Alogna et al., 2014; Tredoux et al., 2021). The practical implication is that although contamination risk is real and important, its magnitude is context-dependent rather than uniform.
10.6.2 Co-witness influence
Witnesses often discuss events with others before or after giving formal statements. Such discussion can contaminate memory. Gabbert et al. (2003) had pairs of participants view different versions of the same event, then discuss what they had seen. Among those who discussed, 71% reported at least one detail they had not witnessed but had heard from their co-witness. Some witnesses incorporated the information into their memory and could no longer distinguish their experience from what they had been told.
Memory conformity occurs through at least two routes. In social compliance, a witness adjusts the reported account to match others while privately retaining a different memory. In genuine memory change, a witness incorporates external information into the memory representation itself. Accounts that appear to corroborate each other may share a common source of misinformation rather than reflecting independent observations (Mojtahedi et al., 2018).
Co-witness contact is not exclusively harmful to memory accuracy. Vredeveldt et al. (2017) and Vredeveldt & Koppen (2018) found that, under controlled conditions, collaborative recall with a co-witness can improve some outputs, particularly when witnesses contribute non-overlapping information and statements are collected independently before discussion. The risk of conformity is greater than the potential accuracy benefit in most investigative contexts, however, and standard practice should be to separate witnesses before obtaining formal statements.
The sequencing of collaborative work is critical. The strongest proposals use a two-stage process: first collect independent statements, then permit controlled collaboration for clarification. Collaborative benefits are therefore plausible, but only after independence has been preserved at the initial account stage (Vredeveldt & Koppen, 2018).
10.6.3 Mugshot exposure and unconscious transference
When a witness views a photograph database (a mugshot album) before attending an identification parade, the individuals they view during that search become familiar. At a subsequent lineup, a person whose face was seen in the mugshot album may feel familiar for that reason, not because they were present at the crime. This familiarity is then misattributed to the crime context (Memon et al., 2002).
The exercise below walks you through this process. You will study a single photograph from a case file, carry out a brief unrelated task, and then view a lineup – noticing whether anything looks familiar and why.
Deffenbacher et al. (2006) conducted a meta-analysis showing that prior mugshot exposure increases the probability that the person whose photograph was included in both the mugshot album and the lineup is subsequently identified. This effect operates even when the individual concerned was not the perpetrator. Beyond familiarity misattribution, prior viewing of a specific photograph can produce a commitment effect: a witness who has selected a particular photograph from a mugshot album may feel bound to maintain that selection at a subsequent lineup.
10.6.4 Repeated identification attempts
Each time a witness views a suspect, whether in a photograph or at a formal procedure, a new memory trace may be created. As this process is repeated, the original encoding of the perpetrator’s face and the subsequent investigative exposures become increasingly entangled. The witness may then struggle to distinguish what they remember from the crime from what they have been repeatedly shown during the investigation. Multiple trace theory (Nadel & Moscovitch, 1997) holds that each retrieval of a memory creates a new, contextually tagged trace, so repeated exposures to a face do not simply strengthen one memory but can generate a family of overlapping traces bound to different contexts.
The policy implication is clear: the first identification procedure is the most evidentially informative one. Subsequent identifications, conducted after prior exposure, are contaminated by that exposure. Where multiple procedures are conducted with the same witness, the first procedure should be documented thoroughly, and the contaminating effect of prior exposure should be acknowledged in evaluation of later procedures. Wells et al. (2020) recommend that: (1) the first identification attempt should be treated as the primary evidential event; (2) witnesses should not be shown suspect images prior to any lineup; and (3) where a prior identification has been made, any subsequent identification by the same witness should be evaluated with prior exposure explicitly in mind and given reduced independent evidential weight.
A related risk arises when investigators run more than one channel with the same witness (for example, photospread, then video lineup, then live parade). If the channels are not equivalently fair, a single biased channel can effectively reveal the suspect and contaminate later channels. Agreement across channels should therefore not be treated as independent corroboration unless each channel was separately documented as fair and blind-administered (Tredoux et al., 2024).
10.6.5 Media exposure
In high-profile cases, the suspect’s face may appear in news coverage before a formal identification procedure. A witness who has viewed that coverage may subsequently identify the suspect for reasons of media-induced familiarity rather than crime-scene recognition. This source of contamination is difficult to control. Investigators can instruct witnesses not to view media coverage, but compliance is difficult to verify. A striking illustration of this mechanism is the case of Donald Thomson, an Australian psychologist who had appeared on television discussing eyewitness research at the time an assault was committed. The victim subsequently identified Thomson from a lineup with apparent confidence. Investigation established that the victim had seen him on television during the assault and had misattributed the source of her memory for his face (Read et al., 1990). The case illustrates how media exposure can produce a confident, sincere, and entirely erroneous identification. This form of error is described in the eyewitness literature as or source misattribution (M. K. Johnson & Raye, 1981; Loftus, 1979).
10.7 System Variables: Interviewing
10.7.1 The cognitive interview
The is an evidence-based protocol developed to increase the quantity and accuracy of information elicited from cooperative witnesses through interview. Its core components, as described by Fisher (1995), are mental reinstatement of the environmental and emotional context of the event, open narrative recall before specific questioning, instruction to report everything without editing for perceived relevance, and use of multiple retrieval routes including mental replay in different temporal orders.
Köhnken et al. (1999) conducted a meta-analysis of 55 cognitive interview studies and found that the protocol produced substantial increases in recall quantity without corresponding increases in error rate. The effects were robust across diverse witness populations and event types. Training in the full protocol produces larger benefits than administration of isolated components. Subsequent reviews have confirmed these findings across a broad range of studies and witness populations.
Implementation quality matters considerably. The protocol is a framework for eliciting memory; its benefits depend on consistent and skilled delivery. Other structured interview variants exist, but the central point for practice is fidelity to evidence-based interviewing principles rather than nominal use of a protocol label (Köhnken et al., 1999). A recurrent implementation problem is that the full is cognitively demanding for both interviewer and witness and is slower than routine question-answer interviewing. Police services may train staff in CI principles but still apply abbreviated versions in practice because of time pressure and workload. The result is partial fidelity: agencies report “using CI” while omitting the components that produce most of its benefits (Memon & Higham, 1999).
10.7.2 Interview structure and timing
Free narrative recall should precede directed questioning. Once a witness is asked specific questions, the structure those questions impose tends to constrain subsequent free recall. The witness may attempt to answer within the boundaries implied by the question rather than generating what they independently remember. Leading questions introduce particular risks. A question that implies an answer, such as “Was the car red?” rather than “What colour was the car?”, can alter the witness’s subsequent account in the direction of the implied answer. The mechanism is the same as the : the question content enters the memory reconstruction process.
Uncertainty language should be preserved in records, not resolved. When a witness says “I think it was him” or “I’m not certain but it seemed like,” those hedges are diagnostically useful. They reflect the witness’s own assessment of their memory quality. Smoothing over uncertainty in records, or pressing the witness to commit to a definite answer, removes information that is valuable for later evaluation of the evidence.
The timing of the interview relative to the event matters. Earlier interviews yield more complete accounts, before forgetting and contamination have progressed. Where the interview must be delayed, witnesses should be advised not to discuss the event with others and should be given the opportunity to provide a contemporaneous written account (Köhnken et al., 1999; Wells et al., 2020).
10.7.3 Eye-closure and other recall aids
One low-cost adjunct to standard interview procedures is asking witnesses to close their eyes during recall. This reduces external distraction and may facilitate the kind of internal mental reinstatement associated with the cognitive interview. Vredeveldt et al. (2015) evaluated this technique in a field study with police witnesses in South Africa, finding that eye-closure produced modest improvements in recall accuracy for specific event details. Eye-closure is not a substitute for trained interviewing, but it is one of several low-resource techniques that can support the recall process under operational conditions where full cognitive interview training is not available. Other low-resource aids, such as structured self-administered interview formats, are also effective (Horry et al., 2021).
10.7.4 Recording
The first interview with a witness is the most evidentially informative. Later accounts are influenced by what occurred in earlier ones. If the first interview is not recorded, the verbatim content of the witness’s account, including uncertainty language, specific wording, and spontaneous detail, is irretrievable. Wells et al. (2020) recommend audio or video recording of all investigative interviews as a basic procedural standard. This is already implemented in England and Wales and has been shown to improve accountability and reviewability of investigative practice. In South Africa, recording of witness interviews is not routinely required, and implementation is variable.
10.8 System Variables: Identification Procedures
10.8.1 Showup identification
A is a procedure in which a witness views a single suspect, typically shortly after the crime and often at the scene or in its vicinity. Showups are more suggestive than lineup procedures because the witness is implicitly led to believe that the person being shown is the suspect. The implicit demand to identify is strong. Meta-analytic evidence indicates that s carry a higher false-identification risk than lineups, especially in target-absent conditions, while correct identifications in target-present conditions can be comparable under some designs (S. E. Clark, 2005; N. M. Steblay et al., 2003). Dock identifications are structurally similar in suggestiveness because the person to be identified is made obvious by context. In a dock identification, a witness is asked in open court to point to the perpetrator; the accused’s position in the dock – the enclosed area where the defendant sits during trial – makes the target of the identification unmistakable, rendering the procedure maximally suggestive.
Despite these limitations, showups are sometimes used when a suspect is apprehended immediately and investigators need rapid confirmation or release. When showups are conducted, documentation is essential: record the witness’s exact response and confidence before feedback, limit the procedure to a single viewing, and interpret any later lineup identification by the same witness in light of the prior exposure (Wells et al., 2020).
10.8.2 Live versus photographic versus video identification
South African law has historically expressed a preference for live (corporeal) identification parades, with photographic procedures available under constraints and video procedures occupying an uncertain legal status. Tredoux et al. (2024) reviewed the empirical basis for this preference and found no consistent advantage for live parades over well-designed photographic or video alternatives. The medium-neutral approach they propose, evaluating any procedure against the same standards of fairness, administration, and documentation, is discussed further in the South African Context section below. Tredoux et al. (2024) also conducted a cost analysis and found live parade organisation substantially more expensive and time-consuming than photographic or video alternatives, a practical consideration that bears on both the frequency with which parades are held and the quality achievable under resource constraints.
10.8.3 Lineup construction and fairness
A lineup is a recognition test. For the test to be valid, the alternatives, called or foils, must be plausible candidates given the witness’s description of the perpetrator. If fillers do not match that description, the procedure is not a fair test: a witness may select the suspect because they match the description rather than because they recognise them from the crime.
Lineup fairness can be assessed quantitatively. The mock-witness method presents the lineup to participants who know the witness’s verbal description but did not witness the crime, and asks them to choose. If mock witnesses select the suspect at above-chance rates, the lineup is biased toward that suspect. Functional/effective size statistics convert mock-witness choice frequencies into an estimate of how many lineup members are genuinely plausible alternatives in practice. A lineup with a nominal size of eight members but an effective size of three functions as a three-person test. Tredoux (1998) provided the inferential framework for testing lineup fairness statistics rather than relying on descriptive values alone.
Effective size (E) is defined mathematically in a 1998 article (Tredoux, 1998), so we will not define it here except to say that it ranges between 1 and k, where k is the number of lineup members. To the extent that E is less than k the lineup departs from perfect effective size (equal to the nominal size of the lineup).
Lineup bias is a related but distinct property. A lineup is biased when mock witnesses, armed with only the witness’s verbal description and no memory for the perpetrator, choose the suspect at above-chance rates. The bias index (Malpass, 1981) is the proportion of mock witnesses selecting the suspect; chance is (1/k). Tredoux (1998) introduced a binomial test framework for inferential evaluation of bias. A lineup can have adequate effective size but still be biased if the suspect is the most-chosen member even when mock witnesses have only the description, and vice versa. Both bias and effective size should be reported in expert evaluations of lineup fairness (Fitzgerald et al., 2023; Tredoux, 1998).
Two selection strategies for fillers exist. Description-based selection requires that each filler plausibly matches the witness’s verbal description of the perpetrator. Suspect-resemblance selection requires that resemble the specific suspect. These strategies can produce different lineups and different levels of fairness, and their relative merits depend in part on the accuracy of the witness’s description.
Nominal lineup size, the count of members, does not capture fairness. A lineup with six members, five of whom are implausible given the witness’s description, functions closer to a two-person test than a six-person one. Fitzgerald et al. (2023) showed that effective-size corrections track innocent-suspect risk in ways that nominal count does not: manipulations that alter plausibility structure change effective size while leaving nominal count unchanged, meaning nominal count fails to detect increased false identification risk.
The mock-witness approach also has known limits. Mock witnesses did not observe the crime and are choosing from a description, not from memory of an event. For that reason, mock-witness statistics are best treated as fairness diagnostics for lineup structure, not direct predictors of eyewitness accuracy. The issue becomes sharper when multiple witnesses provided different descriptions: fairness estimates depend on which description is used to build and test the lineup.
A practical workflow that follows from this is iterative fairness testing. Build fillers from the witness description, run a mock-witness check, replace over-selected members, and re-test until suspect selection approaches chance and effective size reaches an acceptable threshold. This procedure does not eliminate error, but it makes lineup bias measurable and correctable before the lineup is administered (Fitzgerald et al., 2023).
10.8.4 Sequential versus simultaneous presentation
In a simultaneous lineup, the witness views all members at once and makes a single decision. In a sequential lineup, the witness views members one at a time and makes a yes/no decision on each before seeing the next member. Lindsay & Wells (1985) proposed the sequential format to reduce relative judgements: the concern was that witnesses facing a simultaneous array would select the member who looked most like the perpetrator relative to the others, rather than applying an absolute recognition criterion to each.
The sequential format does shift choosing behaviour. Witnesses are more conservative, selecting less often overall. Early experiments reported reduced false identifications under sequential presentation, supporting the practical case for the format (Cutler & Penrod, 1988). The critical question is whether this reflects improved discrimination between innocent and guilty suspects or a shift in criterion without improved memory. Meissner et al. (2005) found results consistent with criterion shift: sequential procedures reduced false identifications but also reduced correct identifications, the pattern expected if witnesses simply raised their threshold for identifying rather than improving their underlying discriminability.
Mickes et al. (2012) applied receiver operating characteristic (ROC) analysis to the simultaneous/sequential comparison. ROC analysis assesses discriminability across the full range of response criteria, separating sensitivity from criterion effects. Their analysis found that when discriminability was the measure, the simultaneous format performed at least as well as the sequential format. The sequential advantage in false identification reduction was accounted for by criterion shift. Wells et al. (2020) review the subsequent debate and note that expert consensus has shifted: the question is no longer which format is superior in the abstract, but whether each format is being evaluated on discriminability or on a particular operating point on the accuracy-criterion tradeoff. Current expert opinion has moved toward a position that procedure format matters less than construction and administration quality. A simultaneous lineup that is fairly constructed and administered without suggestion will produce informative evidence. A sequential lineup that is poorly constructed will not.
10.8.5 Blind administration
A lineup administrator who knows which member is the suspect may influence the witness through subtle, often unintentional cues: pausing at the suspect’s position, reacting to the witness’s hesitation, or adjusting the social dynamics of the session. Greathouse & Kovera (2009) showed that administrators who know the suspect’s identity behave differently from those who do not, and that this affects witness choices even when administrators believe they are conducting the procedure neutrally. The effect does not require deliberate suggestion; knowledge alone is sufficient to alter behaviour in ways that witnesses detect.
A further complication is that administrators who believe themselves to be blind can still influence witnesses if they have access to indirect cues. Smalarz et al. (2021) found that presumed-blind administrators affected both identification decisions and post-identification confidence, underlining the distinction between nominal and genuine blinding.
, where neither the administrator nor the witness knows the suspect’s position, removes this source of influence. It can be implemented through true double-blinding, where a second officer unfamiliar with the case administers the procedure, or through automated presentation that removes the administrator from the identification moment entirely. is recommended in reform guidelines across multiple jurisdictions and is low-cost relative to the risk it addresses (Smalarz et al., 2021; Wells et al., 2020).
South African law and police standing orders have long required that the lineup be conducted by an officer other than the investigating officer. This is sometimes taken to satisfy the double-blind requirement, but it does not. The officer who administers the lineup may still have been briefed on the case, may know which position the suspect occupies, or may simply know who the suspect is from the docket. Any of these is sufficient to produce administrator influence: an officer who knows the suspect’s position, even without any intention to mislead, can inadvertently signal that position through gaze, body language, timing, or phrasing. True double-blinding requires that the administrator genuinely not know either the suspect’s identity or their position in the lineup at the moment of administration – not merely that they are a different person from the investigating officer.
10.8.6 Pre-lineup instructions
Witnesses should be told explicitly, before any identification procedure, that the perpetrator may or may not be present. This has long been a requirment in South AFrican law, but not the law in many parts of the USA until recently. Without this instruction, witnesses often assume presence: the common understanding is that the police would not be conducting a lineup unless they had a suspect, and that the suspect is present. This assumption is not unreasonable, and it produces identifications driven by social expectation rather than recognition. The instruction raises the threshold for choosing and reduces selections in target-absent lineups without substantially reducing correct identifications in target-present ones. The original empirical demonstration is Malpass & Devine (1981), who showed that absent-perpetrator warnings substantially reduced false identifications without comparably reducing correct ones. N. M. Steblay (1997) meta-analysed 18 studies and confirmed the asymmetry: biased instructions increased choices more in target-absent than target-present lineups. S. E. Clark (2005) raised a qualification: in some analyses, correct identification rates in target-present lineups also increased under biased instructions, suggesting the warning may not be entirely costless; it may reduce the probability that guilty suspects are identified as well as reducing false alarms against innocent ones.
Instruction delivery can be verbal, written, or recorded. Written or recorded delivery has the advantage of ensuring consistency across witnesses and providing a verifiable record of what was actually said. The instructions should be delivered before the procedure begins, not embedded in it.

10.8.7 Documentation
The procedure should be documented in ways that permit its later review. This means capturing the witness’s confidence in their own words, immediately after their decision, before any feedback from the administrator or investigator. The verbatim statement is more informative than a summary. A statement like “I’m fairly sure that’s the one, but he looks a bit different than I remembered” carries a different evidential weight from “I’m sure.”
Decision latency, the time elapsed from first viewing a lineup member to making a decision, should also be recorded. Faster identifications tend to be more accurate than slower ones at the population level, though this is a statistical tendency rather than a diagnostic rule for any individual case (Dunning & Perretta, 2002). Video recording of the procedure preserves both the witness’s behavioural response and the administrator’s conduct for independent review. Response time is best treated as a continuous indicator rather than a fixed cutoff, a point developed further in the Decision Time section below (Brewer et al., 2006; Weber et al., 2004).
10.8.8 Measuring eyewitness performance
Understanding how to evaluate the outcomes of identification procedures requires familiarity with some specific measurement concepts. When a lineup is presented, the witness may identify the suspect, identify a filler, or correctly reject the lineup as not containing the perpetrator. In a target-present lineup, the suspect is the actual perpetrator. In a target-absent lineup, the suspect is innocent and the perpetrator is absent. The response categories in each condition have different implications.
The is a widely used, and intuitive measure: it is the ratio of correct identification rate to false identification rate. A high ratio indicates that identifications are more likely to be correct than false. The limitation of this measure is that it conflates two independent properties, discriminability and decision criterion, that have different evidential implications. The (DR) is:
\[\text{DR} = \frac{\text{correct identification rate}}{\text{false identification rate}}\]
For example, if 60% of witnesses in target-present lineups identify the suspect correctly and 20% in target-absent lineups do so, DR = 60/20 = 3.0, meaning a suspect identification is three times more likely from someone who saw the perpetrator than from someone who did not. A DR close to 1.0 indicates the procedure provides little information. However, two procedures can produce the same DR with very different correct and false identification rates, so DR alone does not distinguish a procedure that achieves a DR of 3.0 by suppressing both rates from one that achieves it by elevating both.
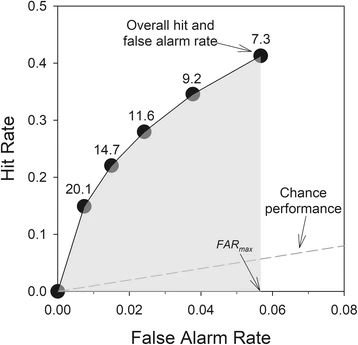
Receiver operating characteristic (ROC) analysis provides a criterion-free measure of discriminability. The ROC curve is constructed by plotting the correct identification rate against the false identification rate across a range of response criteria. The area under the curve reflects how well the witness’s memory distinguishes targets from foils regardless of how conservative or liberal their response criterion is. Gronlund et al. (2014) review the application of ROC analysis to eyewitness identification research. As a concrete example: a simultaneous lineup may produce a correct identification rate of 70% and a false identification rate of 30% at a given confidence threshold, while a sequential lineup produces 50% and 15% at the same threshold. At that operating point the sequential procedure has a lower false-alarm rate, suggesting an advantage. But plotting all confidence levels and computing the area under each curve may show that the simultaneous format has equal or greater area, indicating equivalent or superior overall discriminability; the sequential advantage at the chosen threshold was a criterion shift, not a memory improvement (Gronlund et al., 2014; Mickes et al., 2012).
Confidence-accuracy characteristic (CAC) analysis addresses a question that ROC analysis does not: among witnesses who express a given level of confidence, what proportion are actually correct? The CAC curve plots confidence (expressed at the moment of the identification decision, before any feedback) on the x-axis against the posterior accuracy of that identification on the y-axis. A well-calibrated procedure produces an upward-sloping CAC: a witness who says they are 90% certain should in fact be correct roughly 90% of the time, and a witness who says they are 50% certain should be correct closer to 50% of the time. Research conducted following the 2014 National Academy of Sciences recommendations has confirmed that, under fair procedures and with confidence measured immediately, high-confidence identifications are substantially more likely to be accurate than low-confidence ones (National Research Council, 2014). The practical implication is that confidence measured at the time of the identification decision, before any investigative feedback, does carry diagnostic information. This is contrary to the earlier scientific consensus. One should note thought this diagnostic information degrades rapidly once post-identification contact occurs.
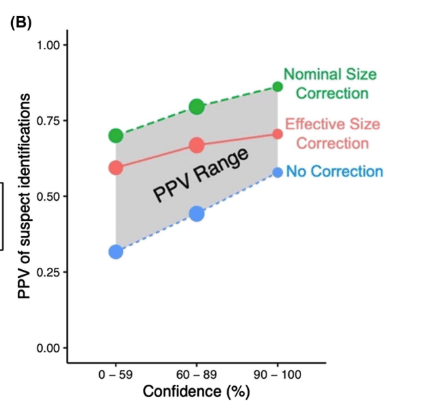
Positive predictive value (PPV) analysis extends the framework to the question that matters most to a criminal justice system: given that a witness has identified this person as the perpetrator, what is the probability that the person is actually guilty? This differs fundamentally from the correct identification rate, which asks “given that this person is guilty, what is the probability of an identification?” PPV depends not only on the accuracy of the procedure but also on the prior probability that the suspect is guilty, viz., the base rate. When suspect guilt rates are low (as they are when investigations cast a wide net), even a procedure with a high correct identification rate can yield a low PPV. Fitzgerald et al. (2023) showed that estimates of innocent-suspect identification risk should be corrected using effective lineup size rather than nominal lineup size, because the effective-size correction is sensitive to lineup bias. Their results have implications for posterior assessments of guilt, especially across confidence levels and lineup conditions, because they make explicit that the risk to an innocent suspect depends on lineup fairness as well as on base-rate assumptions.
10.9 Confidence and Accuracy
10.9.1 The early consensus
The relationship between witness confidence and identification accuracy was a source of concern for several decades of research. Early meta-analyses found correlations in the range of .25, a relationship that is positive but too weak to support treating high confidence as proof of accuracy. This finding, combined with the documented susceptibility of confidence to post-identification feedback, led to broad scientific consensus that confidence should not be given weight in legal proceedings. The correlation was approximately .25 reported in early meta-analyses (Bothwell et al., 1987).
10.9.2 Pristine conditions and the revised framework
Wixted & Wells (2017) argued that the early meta-analyses aggregated studies that varied substantially in procedural quality. When confidence is measured under what they call , meaning immediately after the first identification attempt, before any feedback from investigators or peers, from a witness who has not made prior identifications, using a fair procedure, the confidence-accuracy relationship is considerably stronger (Greenspan & Loftus, 2020). Under these conditions, high-confidence identifications from own-race witnesses have a high probability of being correct. Two qualifications from earlier work remain important. First, Sporer et al. (1995) showed in a meta-analysis that the confidence-accuracy correlation differs markedly between choosers (those who make a positive identification, r = .41) and non-choosers (those who reject the lineup, r = .12). Confidence is therefore more diagnostic for positive identifications than for rejections, and treating the two groups together inflates uncertainty about both. Second, calibration research by Brewer & Wells (2006), using a large sample and confidence categories, showed that eyewitnesses are generally overconfident: expressed confidence exceeds accuracy, particularly at intermediate confidence levels. Under the calibration curve improves, but the overconfidence pattern does not disappear entirely.
Wells et al. (2020) present a broad consensus statement among researchers. The consensus is that confidence, measured immediately and before feedback, is diagnostically useful for high-confidence identifications under fair procedures. The policy implications are that confidence should be routinely captured immediately and that administrators should refrain from any comment, positive or negative, before that capture occurs. An emerging qualification concerns the format in which confidence is expressed. Numeric confidence ratings and verbal confidence statements are not interchangeable; recent work suggests that confidence format can influence how legal decision-makers interpret eyewitness evidence (Pennekamp, 2025). Current policy guidance therefore emphasises verbatim capture of witnesses’ own confidence statements at the time of decision.
10.9.3 Ongoing qualifications
The pristine conditions framework applies most strongly to high-confidence identifications. Low- and medium-confidence identifications remain difficult to interpret without additional information. The framework also applies most reliably within the range of conditions studied, which are predominantly laboratory studies with own-race participants and relatively short retention intervals.
Actual police procedures frequently fail to meet pristine conditions. Administrators give feedback, witnesses make multiple identification attempts, and confidence is often not captured verbatim at the moment of decision. When these conditions are not met, the confidence-accuracy relationship documented under pristine conditions cannot be assumed to apply (Brewer & Wells, 2006; Wells & Bradfield, 1998; Wixted & Wells, 2017).
Cross-racial identifications appear to show a weaker confidence-accuracy relationship than same-race identifications. This is consistent with what one would expect if underlying discriminability is lower in cross-race recognition: reduced signal quality makes confidence a less reliable guide to accuracy (Wright et al., 2003)
10.9.4 Post-identification feedback effects
Wells & Bradfield (1998) demonstrated that a simple confirming statement from an administrator, such as “Good, you identified the suspect,” produces retrospective distortion of the witness’s account. Witnesses who received confirming feedback subsequently reported that they had had a better view of the perpetrator, had paid more attention, had been more certain at the time of identification, and found the identification easier. None of these reports were more accurate than those of control witnesses who received no feedback. The distortion affected not only confidence but a range of other retrospective judgements about the witnessing experience. Feedback inflated reports of how good a view witnesses had had, how clearly they had seen the perpetrator’s face, how much attention they had paid, how certain they had felt at the moment of identification, and how easy they found the task. Witnesses who had expressed hesitation at identification time later described the experience as having felt automatic. None of these inflated reports reflected any actual difference in witnessing conditions or identification quality.
The exercise below demonstrates the procedure used, approximately. You will watch a short video of an incident, identify a suspect, and rate your confidence. You will then receive feedback, and be asked to rate your confidence again.
The mechanism is not deliberate fabrication. Witnesses are reconstructing their past experience, and the feedback provides information that appears relevant to that reconstruction. Charman et al. (2010) proposed the selective cue integration framework to account for this process: witnesses first assess internal memory cues, then, when internal cues are weak, search for and incorporate external cues that are consistent with their identification decision. Confirming feedback functions as exactly such an external cue, and its influence on confidence is strongest when internal cues are weakest, which is to say when the identification is most likely to be inaccurate. The result is that the confidence a witness expresses at trial, after months of investigative contact and confirmation, reflects the investigative process as much as it reflects the original memory. This finding underscores the evidential priority of the first immediate statement. Confidence reported at trial is a poor substitute for confidence captured at the moment of identification.
10.9.5 Decision time
Faster identifications tend to be more accurate. Dunning & Perretta (2002) proposed a heuristic based on their data that identifications made within roughly 10 to 12 seconds of first viewing a lineup were more likely to be accurate than those made after longer deliberation. Subsequent research has refined this finding: latency effects are better treated as continuous than as a strict threshold (Brewer et al., 2006; Weber et al., 2004), and the 10 to 12 second rule does not generalise. Sporer (1992) provided an early systematic analysis of decision time as a postdictor of eyewitness accuracy, finding that choosers who identified correctly were faster than choosers who made errors, and that decision time combined with confidence outperformed either variable alone in classifying identifications as accurate or inaccurate. Sauerland & Sporer (2009) extended this analysis to a field setting, finding that fast and highly confident identifications were substantially more accurate than slower, less confident ones.
The practical implication is that decision latency should be documented. Where identifications are made very quickly, with high confidence, in a fair procedure, and before any feedback, they represent the strongest category of eyewitness evidence. Where identifications are made after prolonged deliberation, with lower confidence or following investigative contamination, they warrant substantially less weight. The overall association between latency and accuracy should not, however, be used to classify any individual identification as accurate or inaccurate: the relationship is just a statistical tendency at the population level.
10.10 Expert Testimony
10.10.1 What experts testify about
Courts in several jurisdictions receive expert testimony on eyewitness science, though this has not, to our knowledge, occurred in South African proceedings to date. Expert witnesses in this area typically do not testify about the specific facts of the case in question. They testify about the scientific findings on factors that affect eyewitness accuracy: the effects of stress, weapon presence, cross-race conditions, post-event contamination, lineup administration, and confidence malleability.
Kassin et al. (1989) conducted an early systematic survey of eyewitness expert opinion, finding consensus among 63 researchers on phenomena including weapon focus, the , lineup instruction effects, and the own-group bias. Kassin et al. (2001) updated this survey and found similar levels of agreement among experts on several core findings. The stress-accuracy relationship, the weapon focus effect, the misinformation effect, post-identification feedback effects, the cross-race effect, and the role of suggestive lineup procedures were among the findings that expert respondents regarded as established and as appropriate for expert testimony. Areas of ongoing scientific debate, such as the precise boundary conditions of the confidence-accuracy relationship, attracted more varied opinion. A more recent survey by Seale-Carlisle et al. (2024) confirmed that agreement remains high on the core findings but noted shifts on confidence-accuracy: a majority of experts now recognise the strength of the confidence-accuracy relationship under pristine conditions, a view not widely held at the time of the Kassin et al. survey.
10.10.2 Admissibility standards
In the United States, expert testimony on eyewitness science is evaluated under the Daubert standard, which requires that testimony rest on scientifically valid methods and be relevant to the facts of the case. Eyewitness research generally meets these criteria, and expert testimony has been admitted in many jurisdictions (Daubert v. Merrell Dow Pharmaceuticals, Inc., 509 U.S. 579, 1993). In South Africa, there is no exact equivalent of the Daubert standard. Rather, expert testimony is generally admissible if it is relevant to the issues in dispute and capable of giving the court appreciable assistance on matters requiring specialised knowledge (Olaborede & Meintjes-van der Walt, 2020). Under this approach, expert evidence on eyewitness science is in principle admissible although we are not aware of any particular case where it has been admitted.
10.10.3 The reform debate
Whether expert testimony is necessary, or whether expert evidence alone can correct eyewitness misconceptions, remains contested. Testimony that summarise the scientific findings (for example, noting that high stress can impair memory, that lineup administrator knowledge can affect witness behaviour) are less effective than expert testimony in correcting false beliefs, according to experimental studies (Cutler et al., 1989). Brigham & Bothwell (1983) showed that prospective jurors substantially overestimated eyewitness accuracy, providing empirical grounds for the argument that expert correction is needed. National Research Council (2014) recommended that courts should permit expert testimony on eyewitness evidence and that such experts should be made available to defendants who cannot afford their own. In South Africa, where criminal trials do not use juries, the relevant audience for expert testimony would be magistrates, judges, and any lay assessors sitting with the court. Expert testimony in this context would address the finder of fact directly: trained legal professionals who may have sophisticated evidentiary reasoning but may lack specialist knowledge of the eyewitness science literature. The potential impact of well-presented expert evidence in this setting may differ from the jury context that most of the reform literature addresses.
10.11 The South African Context
10.11.1 Legal framework
South African law provides a statutory basis for identification parades where identity is contested, while detailed parade procedures are largely set out in police instructions and case law (Tredoux et al., 2024). Courts apply cautionary rules when eyewitness evidence is the primary basis for conviction. The rules direct courts to consider the circumstances of the observation, the opportunity for accurate identification, and any consistency between the witness’s initial description and the person ultimately identified.
Dock identification, in which a witness is asked to point out the perpetrator in the courtroom, is still used in South Africa. This is among the most suggestive possible forms of identification: the witness is implicitly told that the person they should identify is sitting in the dock. The suggestiveness is difficult to overcome with a cautionary direction, and the procedure lacks any of the safeguards that formal parade procedures are designed to provide. In practice, dock identification in SA courts typically functions as a confirmation of a prior out-of-court identification rather than as a primary identification event. Its probative weight is therefore limited, and courts have been advised to treat it accordingly.
The SA legal framework reflects a substantive historical commitment to caution about eyewitness evidence. Its structural limitation is that it operates at the point of adjudication, after all identification procedures have been completed. The procedural quality of the investigation determines whether usable evidence arrives at court. Judicial caution cannot recover quality lost during collection (Tredoux et al., 2024).
10.11.2 Live versus alternative procedures
Current SA legal preference is for live identification parades. Photographic procedures are available under specific conditions, and video procedures have a contested legal status. The premise that live parades are more reliable than photographic or video alternatives was assessed by Tredoux et al. (2024), who reviewed the empirical basis for this preference. Their conclusion is that no consistent empirical advantage for live parades has been established. Live parades also impose operational costs that affect procedural quality, particularly in under-resourced settings.
Tredoux and colleagues propose a medium-neutral approach: any identification method should be evaluated against consistent procedural standards rather than preferred or excluded by type. Acceptance of this approach would require legislative or regulatory change, as current SA law does not treat media neutrally. The operational case for flexibility is strong, and international reform has generally moved in this direction.
10.11.3 Cross-race identification in South Africa
South Africa’s demographic context, and its high levels of crime makes cross-race identification one of the most practically significant estimator variables in the local setting. The findings of J. K. Lee & Penrod (2022), who summarised 159 studies on the other-race bias, show reduced discriminability and elevated false alarm rates for other-race faces across all groups, not only for White observers. This cross-group generality is relevant in a South African context where crimes cross multiple racial boundaries.
The practical consequence is that identification evidence in criminal cases in which identifications are across group lines can carry elevated error risk at baseline. This does not make correct identification impossible; it does mean that cautionary treatment of cross-race identifications is well-supported by the evidence, beyond any generalised caution that courts already apply. Court and investigative awareness of this specific risk is important, as is documentation of the racial conditions under which the identification was made. South African research has documented own-group biass directly (P. M. Chiroro et al., 2008; Horry et al., 2010; Wittwer et al., 2019), with patterns that are consistent with the asymmetry discussed in the estimator-variables section.
10.11.4 Multiple-perpetrator crimes
The majority of eyewitness research uses single-perpetrator experimental designs. Multiple-perpetrator crimes, which are common in South Africa, present demands that single-perpetrator research does not directly address. When multiple offenders are present, witnesses must encode multiple faces under conditions of divided attention. Nortje et al. (2020) found that multiple-perpetrator cases were common in the experience of South African detectives, constituting a routine challenge for investigative practice rather than an exceptional scenario. They must also bind specific actions to specific individuals: who did what. Face recognition and action-attribution are distinct memory tasks.
Nortje et al. (2020) surveyed South African detectives and found that multiple-perpetrator cases were common in their operational experience, and that standard identification parade procedures were routinely adapted to accommodate multiple suspects, often under logistical pressure and without formal policy guidance. These adaptations were variable in fairness and difficult to evaluate retrospectively.
The evidential implications are direct. An identification of one suspect in a multiple-perpetrator case does not imply equal evidential quality for another suspect identified in the same investigation. Separate parade procedures, separate fairness assessments, and separate documentation are required for each suspect. Role attribution, that is, which perpetrator performed which actions, should be recorded as a distinct evidential step, separated from identity decisions at the time of the identification procedure rather than reconstructed afterward.
Standard single-suspect parade logic does not automatically translate to multiple-suspect situations. Formal policy guidance for this common scenario is overdue.
10.11.5 Reform priorities
Three areas of reform are most directly relevant to South African practice.
First, identification procedures should meet documented fairness standards. Fillers should be selected to match the witness’s description. Administration should be blind or automated to remove administrator influence. A standard pre-procedure instruction should inform the witness that the perpetrator may or may not be present. Confidence should be captured immediately and verbatim, before any feedback. These standards are not new; they appear in reform guidelines across multiple jurisdictions and are supported by the evidence base. Notably, several of these requirements have been part of South African police practice since the 1950s: Rust & Tredoux (1998) documented that pre-lineup instructions informing the witness that the perpetrator may or may not be present were already required by police orders, predating the formal psychological reform literature on this topic by decades.
Second, investigative interviewing should use evidence-based protocols. The cognitive interview and related structured approaches have documented benefits. Training in these methods is not without cost, but it produces measurable improvements in the quality of information that witnesses provide. Pressing witnesses for categorical answers when they express uncertainty removes information that is useful for later evaluation. Uncertainty should be preserved in records.
Third, policy for multiple-perpetrator cases should be developed and published. Current practice relies on informal adaptation of single-suspect rules. Given the frequency of multiple-perpetrator crimes in South Africa and the specific memory demands they impose, formal published guidance is a practical necessity. The SA research conducted by Nortje et al. (2020) provides an empirical starting point for such policy development.
10.12 Special Populations
10.12.1 Child witnesses
Children can be reliable witnesses to crimes they have directly observed, but their accuracy is more sensitive than adults’ to the conditions under which evidence is collected. Younger children are more suggestible: they are more likely to accept and report misinformation embedded in questions or provided by authority figures. In target-absent lineup conditions, young children show higher false identification rates than adults. The age at which children reach adult-like performance on identification tasks varies with the specific task, but most research suggests that performance does not consistently reach adult levels until early adolescence. Pozzulo & Lindsay (1998) found in a meta-analysis that children over age 5 showed comparable correct identification rates to adults in target-present lineups but substantially higher false identification rates in target-absent lineups, with the gap most pronounced in younger children.
Protective interview protocols have been developed specifically for child witnesses. The NICHD Investigative Interview protocol is among the most thoroughly evaluated. It uses open-ended prompts, avoids specific questions until an open narrative has been completed, and refrains from option-posing questions that suggest particular answers. When trained interviewers apply structured protocols of this kind, children’s accounts are more complete and show lower rates of incorporation of interviewer-suggested information (P. Chiroro & Muller, 2005; Lamb et al., 2002; Orbach et al., 2000).
Standard adult identification procedures may also need adaptation for child witnesses. Pozzulo and colleagues developed the elimination procedure specifically for this purpose: children first reject photographs they are certain do not show the perpetrator, then make an identification decision from the remaining members (Pozzulo & Lindsay, 1999). This two-stage approach can reduce children’s false identification rates in some age groups and testing conditions. The adjustments required depend on the child’s age and developmental level.
10.12.2 Elderly witnesses
Face recognition ability declines with age, as does memory more generally. Older witnesses show lower correct identification rates and, in some conditions, higher false identification rates than younger adults. This pattern reflects changes in the underlying memory system rather than lower motivation or effort (Lamont et al., 2005).
An additional factor is the own-age bias, also called the cross-age effect: people tend to recognise faces from their own age group more accurately than faces from other age groups. This means that elderly witnesses identifying younger perpetrators, and younger witnesses identifying elderly perpetrators, face an accuracy disadvantage analogous to the own-group bias. The magnitude of the own-age bias is smaller than the own-group bias on average, but it is reliable (Martschuk & Sporer, 2018).
Practical implications for evidence evaluation include greater caution in assessing confident identifications from elderly witnesses, and awareness that age-related decline is gradual and variable: not all elderly witnesses show equivalent impairment.
10.12.3 Police as eyewitnesses
Police officers sometimes witness crimes directly, and questions arise about whether their training and occupational experience confer any accuracy advantage over civilian witnesses. The common assumption is that officers are better observers, and some expert opinion has endorsed this view. The empirical evidence is more equivocal. Tupper et al. (2023) compared police trainees and laypeople on identification accuracy across portrait, profile, and body-only lineup formats. Police trainees showed higher hit rates and correct rejection rates for frontal portrait lineups, but the advantage did not extend consistently to other formats. Calibration of confidence to accuracy was similar for both groups. For peripheral and body-only lineups, both groups were comparably overconfident. The authors conclude that expert opinion on police superiority has shifted toward uncertainty: no reliable, general accuracy advantage for police over laypeople has been established. Where police officers are witnesses to crimes, their evidence should be evaluated by the same procedural standards applied to civilian witnesses.
10.13 Technology and Emerging Issues
10.13.1 Computerised and video lineup systems
Computerised lineup systems offer several procedural advantages. Instruction delivery is consistent across witnesses and procedures. Response timing can be recorded automatically. The sequence of photographs and the interval between members can be standardised in ways that are difficult to achieve with physical arrays. Automated administration removes the administrator from the decision moment, which addresses the administrator expectation problem. These advantages have led to use of computerised and video-based systems in several jurisdictions (Valentine et al., 2003).
10.13.2 AI-generated fillers
The operational bottleneck in lineup construction is often the search for appropriate fillers. Finding individuals who match the witness’s description in terms of age, race, build, and distinctive features, and who are willing to participate, takes time and may produce lineups where the best available fillers are not actually good matches. AI-generated face images have therefore been discussed as a possible tool for producing candidate fillers and composite-like outputs, but direct evaluation in eyewitness lineup settings remains limited (Tredoux, Frowd, et al., 2023).
Fairness testing of AI-generated lineups remains necessary. Generating a face to match specified parameters does not guarantee that the resulting lineup is experienced as fair by actual witnesses. Mock-witness testing should be applied to AI-generated lineups in the same way it is applied to conventional lineups. An additional concern is that people can struggle to distinguish AI-generated images from photographs of real individuals, especially without specialised training or aids (Kramer & Cartledge, 2024; E. J. Miller et al., 2023), raising questions about the probative and presentational properties of synthetic lineup members. Regulatory and policy attention to synthetic images in legal proceedings is still developing.

Synthetic fillers also raise a similarity-calibration problem. If generated fillers are too dissimilar to the suspect, the lineup is biased by obvious mismatch; if they are too similar, the test becomes unrealistically difficult and can suppress correct identifications. Operationally, lineup construction needs a bounded similarity zone between those extremes. Automated generators may make this calibration more tractable, but they do not remove the need for empirical fairness validation with human judges (Menne et al., 2023).
10.13.3 Facial recognition technology
Automated facial recognition systems compare a probe image against a database and return candidate matches. Their role in eyewitness testimony must be carefully circumscribed. Facial recognition outputs should be treated as investigative leads, not as identification evidence. A system match tells investigators where to look; it does not establish identity. The confusion of these two functions is a source of serious misuse in practice.
Facial recognition systems show performance disparities across demographic groups. Systems trained predominantly on one demographic produce less accurate results for other groups. This disparity is well-documented in large-scale evaluations and has led to documented wrongful arrests in the United States (Grother et al., 2019). South Africa’s demographic diversity and relatively high crime rates, combined with potential investment in surveillance infrastructure, make governance of facial recognition use a matter of practical urgency. A separate chapter in this volume addresses facial recognition technology in detail.
10.14 Conclusion
Eyewitness testimony is neither inherently reliable nor inherently unreliable. Its probative value depends on the conditions under which the crime was witnessed, on what happened to the witness’s memory between the event and the identification, and on how the identification procedure was conducted. These determinants are measurable, and for system variables, they are modifiable.
The mechanisms are not contested in any fundamental sense. Stress, weapon presence, retention interval, cross-race conditions, and post-event contamination predictably affect memory quality. Lineup construction, blind administration, instruction wording, and confidence documentation affect identification outcomes. The confidence-accuracy relationship is real, conditional on procedural quality, and susceptible to feedback contamination.
South African research contextualises these mechanisms for a jurisdiction with specific conditions: a legal framework built around live identification parades, a high prevalence of multiple-perpetrator offending, and the demographic patterns that make cross-race identification common in criminal cases. The international and local bodies of work converge on the same practical conclusion. The quality of eyewitness evidence is determined primarily by procedural quality at the front end of evidence collection. Improving that quality requires deliberate and documented attention to procedure, not only judicial caution at the adjudication stage.
Witnesses who err are not usually dishonest. They are subject to the same cognitive constraints that govern all human memory: imperfect encoding, constructive retention, and reconstructive retrieval. The response to that constraint should be procedural and systemic.
10.15 Test Yourself
10.16 Open-answer Check-in
In South Africa and the United Kingdom, lineups are more formally known as ‘identification parades’ or ‘identity parades’.↩︎