9 Face research
9.1 Introduction
Face recognition is a central topic in cognitive psychology because it is at the intersection of perception, memory, and social cognition. Most adults can recognise large numbers of individual faces, sometimes cited as around 5,000 people across a lifetime (Jenkins et al., 2018). That capacity matters for everyday interaction and for applied settings where identity decisions are common. Eyewitness identification depends on face memory. ID checking depends on unfamiliar face matching. CCTV and other surveillance systems now produce vast archives of face images, and those images are only useful if people or systems can interpret them well.
Face recognition also varies sharply across individuals. (face blindness) is a neuropsychological condition, sometimes resulting from brain damage and sometimes developmental in origin, in which a person cannot recognise faces, sometimes not even their own (Duchaine & Nakayama, 2006a). Studying prosopagnosia reveals the existence of specialized neural machinery for face processing by observing what happens when that machinery is disrupted. At the other end of the spectrum, s possess face memory that is far above average and can identify large numbers of faces even with very brief exposure (Bobak et al., 2016; Russell et al., 2009). Both extremes are informative for theory because they show how face processing can fail or excel without necessarily implying changes in general vision or intelligence.
This chapter has several aims. It addresses the question of how faces are represented and why researchers argue that configuration and context matter as much as individual features. It examines whether faces engage dedicated cognitive and neural mechanisms or whether they are simply a particularly well-practiced class of stimulus. It connects basic research to applied tasks such as composite construction, unfamiliar face matching, and automated face recognition. These are not isolated questions: the study of face recognition moves constantly between laboratory demonstrations, neuroimaging, clinical neuropsychology, and real-world applications, and throughout the chapter the aim is to present findings from each of these areas.
9.2 How faces are encoded
A useful starting point is the tension between featural and configural processing of faces. Featural processing emphasizes parts such as eyes, nose, and mouth. Configural (or holistic) processing emphasizes the relations among those parts: distances, alignments, and overall structure. Most researchers now treat this as a combination rather than a strict either/or, but the balance matters for understanding both recognition and its failures.
One line of evidence comes from eye-tracking. When people inspect a face, they fixate the eye region more than other areas (Henderson et al., 2005), suggesting that certain features carry more weight in encoding and recognition.
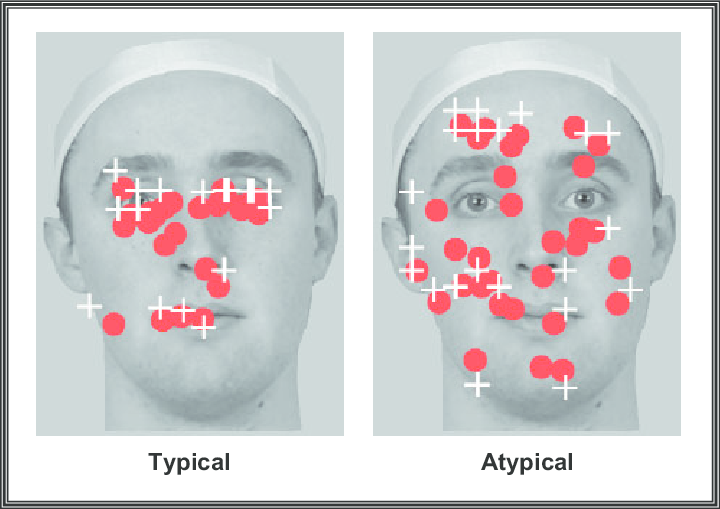
A complementary question is how encoded faces are stored. The dominant theory is Valentine’s (1991) model: in this model, each face is represented as a point in a high-dimensional space, where each dimension corresponds to a facial property such as nose width, inter-eye distance, or more abstract configural aspects. An average face sits at the centre of this space, and individual faces are distributed around it. The distance of a face from the centre reflects its distinctiveness: how atypical or unusual it is. Distinctive faces, further from the centre, have fewer near-neighbours in the space and so are less likely to be confused with other stored faces. Typical, ordinary-looking faces cluster near the centre and are more confusable. This geometry provides a unified account of several phenomena examined in later sections, namely caricature effects, distinctiveness advantages in recognition, and the .
9.3 Internal versus external features
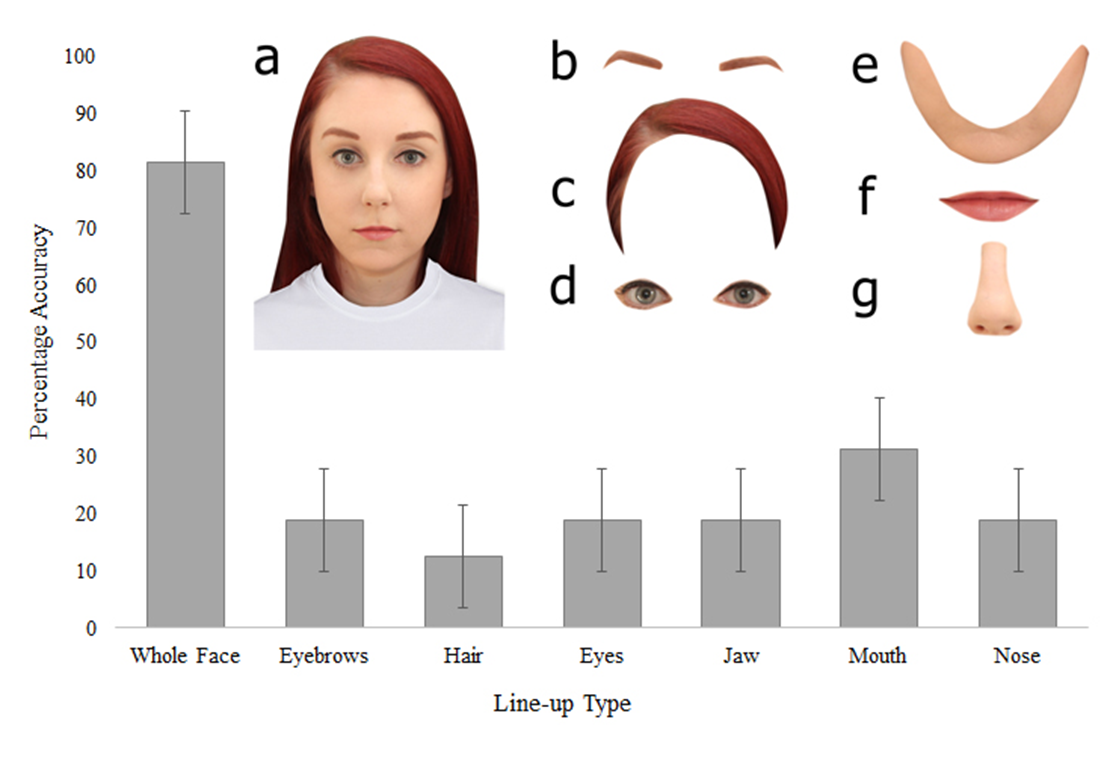
Studies of internal versus external features illustrate this balance. Internal features refer to eyes, brows, nose, and mouth, while external features include hair, head shape, and ears. A group of researchers that worked in Aberdeen, UK, in the 1970s and 1980s showed that for familiar faces, internal features are particularly diagnostic, whereas for unfamiliar faces the advantage is smaller or absent (Ellis et al., 1979). Their experiments demonstrated that participants recognised familiar faces much better from just the inner face, that is with hair and outer shape masked out, than from the outer features alone. For unfamiliar faces, however, removing external features impaired recognition just as much as removing internal features. With familiarity, observers learn stable internal structure; with unfamiliar faces, they rely more on the whole image, including hair and other external cues.

9.4 The role of individual features
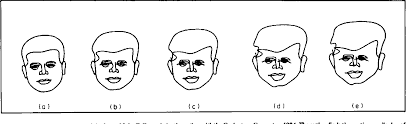
Distinctive features also matter. A highly unusual chin or mouth can be recognised in isolation. A feature that deviates strongly from the average face can cue identity: highly unusual eyes, a distinctive chin, or prominent lips may be recognisable in isolation. Two faces with highly distinctive individual features are shown below. Both can be identified from isolated features alone, which is unusual. It is thought that most other faces are recognised throught configural information.
_by_Alan_Light.jpg)
.jpg)
Criminals sometimes exploit the importance of features by altering easily changed aspects of their appearance e.g. hairstyle, facial hair, glasses, to reduce their recognizability. Conversely, forensic artists creating police sketches often emphasize the distinctive features described by witnesses precisely because those features can cue identity. Relying on isolated features has real limits. Most faces do not have ultra-distinctive single features, and recognizing a person usually requires seeing the face in its normal context. In unpublished work, Kempen and Tredoux reported a marked drop when participants identified people from isolated features rather than whole faces. That pattern is consistent with published part-whole findings in face recognition, where identification is reliably better for whole faces than for isolated parts (Tanaka & Farah, 1993).
9.5 Configural and holistic processing
Evidence for configural processing is strong. One example is recognition of heavily pixellated faces. When an image is reduced to as little as a 16 × 16 grid of large pixels, fine feature details disappear entirely. If recognition were purely feature-based, such severe degradation should make identification impossible. Yet familiar faces can often be recognised from such coarse pixelations: people use the overall pattern of dark and light regions corresponding to hair, eyes, and skin rather than crisp feature details. That suggests that global structure and relative contrasts carry recognisable information even when features are blurred.
![]() .
.
The (Yin, 1969) provides converging evidence. Turning a face upside-down impairs recognition more than it does for most objects, even though the features are still visible. Inversion does not alter any individual feature: the eyes, nose, and mouth are all still present, but it disrupts the spatial arrangement that normal face processing relies on. When that upright configuration is not available, we cannot easily engage , and performance drops, even though feature-by-feature analysis is in principle still possible.

The face inversion effect. Both images show the same person (Tyla, South African singer). The inverted version on the left is hard to identify despite containing identical feature information; rotating it upright restores normal recognition. Upright configuration, not the features themselves, drives familiar-face identification.
A powerful demonstration here is that of the so-called ‘’ (Thompson, 1980). When a face is inverted, local feature distortions that are effected e.g., eyes and mouth rotated to normal orientation while the rest of the face remains inverted, can be hard to notice. When the image is turned upright, the same distortions become obvious because they violate the expected spatial relationships. The illusion is not about the features themselves but about their configuration: when is engaged in the upright view, violations of expected spatial relations are immediately detected; when it is not engaged, as in the inverted view, we fail to perceive the anomalies.

Composite (or ‘split-half’ or ‘chimeric’) faces provide a further test. When the top half of one face is aligned with the bottom half of another, people struggle to identify either half. When the halves are misaligned, identification improves. This split-half effect shows that holistic fusion interferes with part recognition (Young et al., 1987). The brain seems to insist on seeing a coherent face and thus has difficulty seeing two halves as separate identities; holistic fusion is automatic and persists even when it is disadvantageous.

9.6 Caricature effects
Caricature studies extend the evidence in favour of the configural view. Brennan showed that exaggerating a face away from an average prototype can improve recognition (Brennan, 1985). Her computer-generated caricatures, created by mathematically amplifying the deviation of a face from an average, led to significantly better recognition than either the original images or anti-caricatures (faces modified toward average).
Benson and Perrett found that photographic caricatures can be recognised faster than the originals, and that this advantage can extend to unfamiliar faces (Benson & Perrett, 1994). Later work confirmed that the effect is robust but depends on the degree of exaggeration and task demands (K. Lee et al., 2000; Rhodes et al., 1987). The broader point is that faces appear to be encoded relative to a norm, and deviations from that norm can sharpen identity signals.
Go to warpfaces.cogbook.org. Load the test face image and test parameters, you may need to experiment with this. Notice how even mild exaggeration sharpens the sense of identity, whereas moving toward average makes the face more generic.
Taken together, pixellation robustness, the , the , and chimeric faces provide converging evidence that holistic (or configural) processing is a hallmark of face perception. Our visual system is tuned to the typical upright configuration, and even subtle changes in that configuration can disrupt recognition. Featural and configural processing are not mutually exclusive as normal face recognition involves an interplay of the two, but the holistic aspect plays a decisive role in everyday perception. We can think of holistic processing as the default strategy for upright faces: fast and efficient for the kinds of stimuli we have so much experience with. Feature-based scrutiny may come into play when holistic recognition fails or when we deliberately compare unfamiliar faces, but the evidence suggests that our cognitive system handles faces differently from most other objects (see the later section on neural substrates).
It is worth noting that researchers distinguish between two levels of configural processing: first-order configural processing refers to the basic arrangement shared by all faces i.e., two eyes above a nose above a mouth, while second-order configural processing refers to the relations (e.g., distances) between features in a particular individual’s face. First-order processing is necessary to identify something as a face at all; second-order processing is what distinguishes one face from another. The effects described above, that is to say inversion, the Thatcher illusion, and the chimeric effect, are primarily driven by disruption at the second-order level.
9.7 Face aftereffects and norm-based coding
The findings of a caricaturing advantage imply that faces are represented relative to a norm or average. A more direct test comes from ‘adaptation’ experiments. After viewing a face for a few seconds, perception of a subsequent face shifts in the opposite direction, following the same logic as motion aftereffects or colour aftereffects. Leopold et al. (2001) demonstrated an identity aftereffect: after adapting to an “anti-face” (an image morphed away from a target identity), participants recognised the actual target face more readily. The adaptation shifted the perceptual baseline, making the true face seem more distinctive. Related work on figural aftereffects showed that adapting to a compressed face causes subsequently viewed normal faces to appear expanded, and vice versa (Rhodes & Jeffery, 2006; Webster & MacLin, 1999). Together, these effects show that the face system continuously recalibrates against a running average of recently encountered faces, consistent with Valentine’s face space model but adding a dynamic, adaptive dimension to it.
The figure below illustrates the logic of an identity aftereffect. Starting from a veridical face (centre), a caricature exaggerates its features (right) while an anti-face compresses them toward average (left). After prolonged viewing of the anti-face, the veridical face appears shifted toward the caricature direction, evidence that adaptation has recalibrated the perceptual norm. Rhodes and Jeffery (2006) produced systematic demonstrations of this kind of figural aftereffect, and the paradigm now serves as a standard test of .

The that we see in the adaptation effects may explain several otherwise puzzling findings. It accounts for the caricature advantage (amplifying deviation from the norm sharpens the signal), the distinctiveness advantage in recognition (atypical faces are more memorable because they occupy a less crowded region of face space), and the (the norm is tuned to frequently encountered faces, so faces from less-familiar groups cluster near an unfamiliar region of the space with coarser resolution). This adaptive quality of the norm, i.e. its sensitivity to recent experience, is consistent with two related phenomena. First, prolonged exposure to a particular face population shifts the norm toward that population, changing how new faces in the same range are perceived (Webster & MacLin, 1999). Second, own-group bias is associated with contact history, with meta-analytic evidence indicating smaller bias where cross-group contact is greater (Meissner & Brigham, 2001). More direct evidence for norm-based mechanisms comes from the adaptation paradigm itself: after adapting to a distinctive face, viewers become less sensitive to subsequent faces in that part of face space, exactly as the model predicts if the local norm has shifted (Leopold et al., 2001).
9.8 Are faces special? Expertise versus specialization

The predominance of configural processing for faces raises a broader question: do faces engage dedicated cognitive and neural mechanisms, or are they simply a particularly well-practiced class of stimulus? This debate has been pursued for decades, and several lines of evidence bear on it.
9.8.1 Infant behaviour and early bias
Even newborn babies, with very limited visual experience, prefer to look at face-like patterns over scrambled features. In studies, newborns track a moving paddle with a face-like configuration e.g., two dots for eyes and one for mouth in the proper arrangement, for longer than a paddle with the same elements in a jumbled layout. Morton and Johnson proposed that this early bias stems from a subcortical mechanism they called (M. H. Johnson et al., 1991), which directs infants’ attention toward faces before extensive visual experience has accumulated. is supplemented by CONLERN, a learning mechanism that refines face recognition through exposure as the cortical visual system matures. This model suggests that the brain arrives with a predisposition toward face-structured input, which is then sharpened by experience.
9.8.2 Neuropsychological evidence
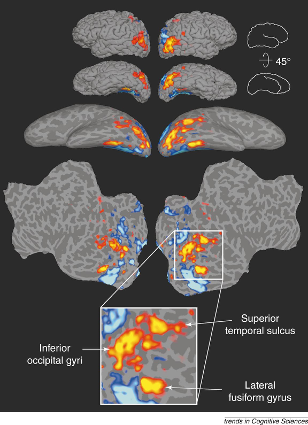
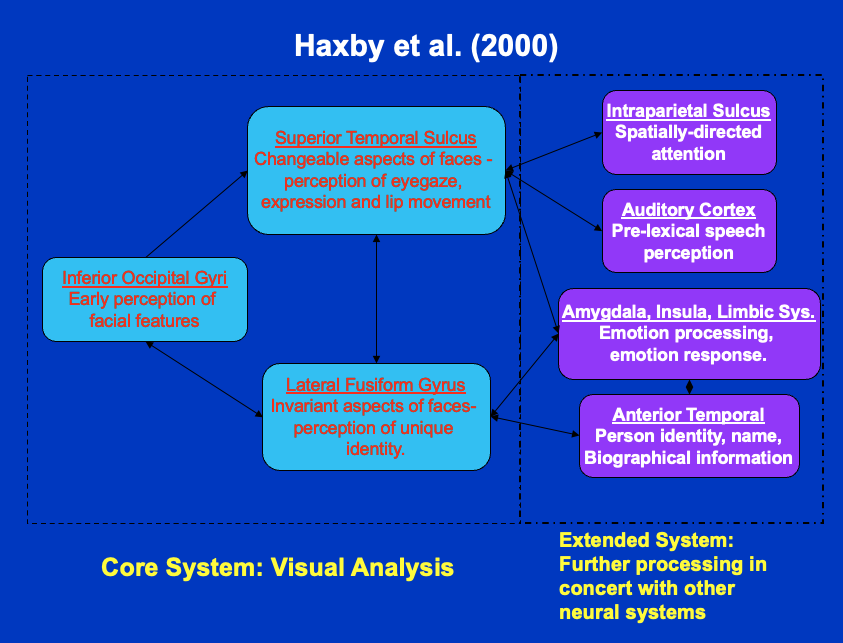
provides some of the strongest evidence for neural specialization. Damage to the fusiform gyrus, typically in the temporal lobe, can impair face recognition while leaving recognition of objects and scenes intact. This double dissociation (cases where patients cannot recognise faces but can recognise objects, and vice versa) points to dedicated processing (Duchaine & Nakayama, 2006a). The neurologist Oliver Sacks described his own lifelong prosopagnosia in The Mind’s Eye (Sacks, 2010), and the American artist Chuck Close developed distinctive strategies for painting portraits despite being unable to recognise faces. Both cases illustrate that the condition does not affect general visual ability or intelligence, since both Sacks and Close clearly functioned at high cognitive levels. Kanwisher and colleagues identified a region they called the (FFA), which responds much more strongly to faces than to other visual stimuli in functional neuroimaging (Kanwisher et al., 1997). Other regions also contribute: the occipital face area and the superior temporal sulcus (STS) play roles in encoding gaze direction and expression. Haxby and colleagues proposed that these regions form a distributed system, with different areas handling different aspects of face information (Haxby et al., 2000).
9.8.3 The expertise alternative
Not everyone agrees that faces are neurally special. Gauthier and colleagues showed that when people become experts at distinguishing novel object classes such as “Greebles” (invented creatures with shared configurations but different parts) the fusiform area also responds more strongly to those objects, and people even begin to show inversion effects for them after training. This expertise hypothesis proposes that the brain has a flexible capacity that gets tuned to any category requiring fine within-category discrimination, and faces simply happen to be the category all humans practice on extensively. Bird-watchers and car enthusiasts show similar fusiform activation when viewing birds or cars, respectively (Gauthier et al., 2000). Gauthier and colleagues argued the expertise case through a series of experiments (Gauthier et al., 1999; Gauthier & Tarr, 1997). In the Greebles paradigm, participants trained to individuate these novel creatures began to show inversion effects and FFA activation for Greebles, effects previously considered diagnostic of face-specific processing.
Proponents of the neural specialization position counter that no other category produces as robust or as early an effect as faces. Kanwisher and others found that the FFA responds to faces even in individuals who have no unusual expertise with any other visually homogeneous category, and that transcranial magnetic stimulation (TMS) to the face area disrupts face but not object recognition. Developmental data also support specialization: the early bias observed in newborns appears before any extensive face-processing experience could have occurred.
9.8.4 Evidence from other species
Other primates and even some non-primate species show evidence of specialized face perception. Monkeys have face-selective brain regions and exhibit strong inversion effects for faces. Sheep can remember dozens of other sheep faces and recognise them after long separations. These findings suggest the existence of an evolutionarily ancient mechanism for identifying conspecifics by their faces, one shared across social species.
The macaque face-patch system was established by Tsao and colleagues (2006), who used fMRI to locate face-selective regions and then confirmed with single-unit recording that nearly all neurons within these patches responded selectively to faces. For sheep, the key demonstration comes from Kendrick and colleagues (2001), who showed that sheep can recognise dozens of individual sheep faces, show inversion effects for sheep faces, and preferentially process faces from the left visual field, paralleling human lateralisation.
9.8.5 Where the consensus stands
Current thinking leans toward a middle ground. Faces do engage processes that are domain-specific, but experience and learning are also involved in refining those processes. A useful way to think about it is that there may be a neural predisposition or template for face processing, making faces special in the brain’s organization, and that exposure makes this processing precise. The automatic and involuntary quality of holistic processing visible in the chimeric face effect indicates that the cognitive system handles faces differently from most other stimuli. Yet if one were to spend extensive time training on a different category, some similar processing characteristics might emerge, though perhaps not to the full extent seen with faces.
Studies of clinical populations provide further evidence. Individuals with autism spectrum disorder often show reduced holistic processing and greater reliance on individual features when viewing faces; some studies report greater fixation of the mouth region rather than the eyes, which is the reverse of the typical pattern (Griffin et al., 2023). People with Williams syndrome show heightened social interest in faces but paradoxically impaired face recognition: a dissociation that highlights how social motivation and perceptual processing can separate.
9.9 Models and mechanisms of face recognition
The best-known functional model of face recognition and processing is Bruce and Young’s (1986) account, which separates structural encoding from later stages such as recognition and name retrieval (Bruce & Young, 1986). It is not a neural model, but it provides a useful map of the processes a system must accomplish. A key feature of the model is that recognition, naming, and access to other semantic information about a person are separable stages. A familiar face can trigger a sense of recognition - “I know that person” - without immediately producing the person’s name. This dissociation between recognition and naming is well documented and is naturally explained by the architecture of the model.
A brief digression now to clarify what is meant by ‘a functional model’. Such a model describes cognition in terms of information-processing stages: what representations are formed, what operations are applied to them, and in what sequence. It says nothing about which neurons or brain regions implement these stages; the neural substrate is left open. This makes functional models useful for organising behavioural data and for generating predictions about dissociations, that is, patterns where one process can fail while another is preserved, without committing to a biological implementation. Bruce and Young’s account is functional in this sense: it specifies stages such as structural encoding, face recognition units, person identity nodes, and name retrieval, and predicts which combinations of impairment are and are not possible.
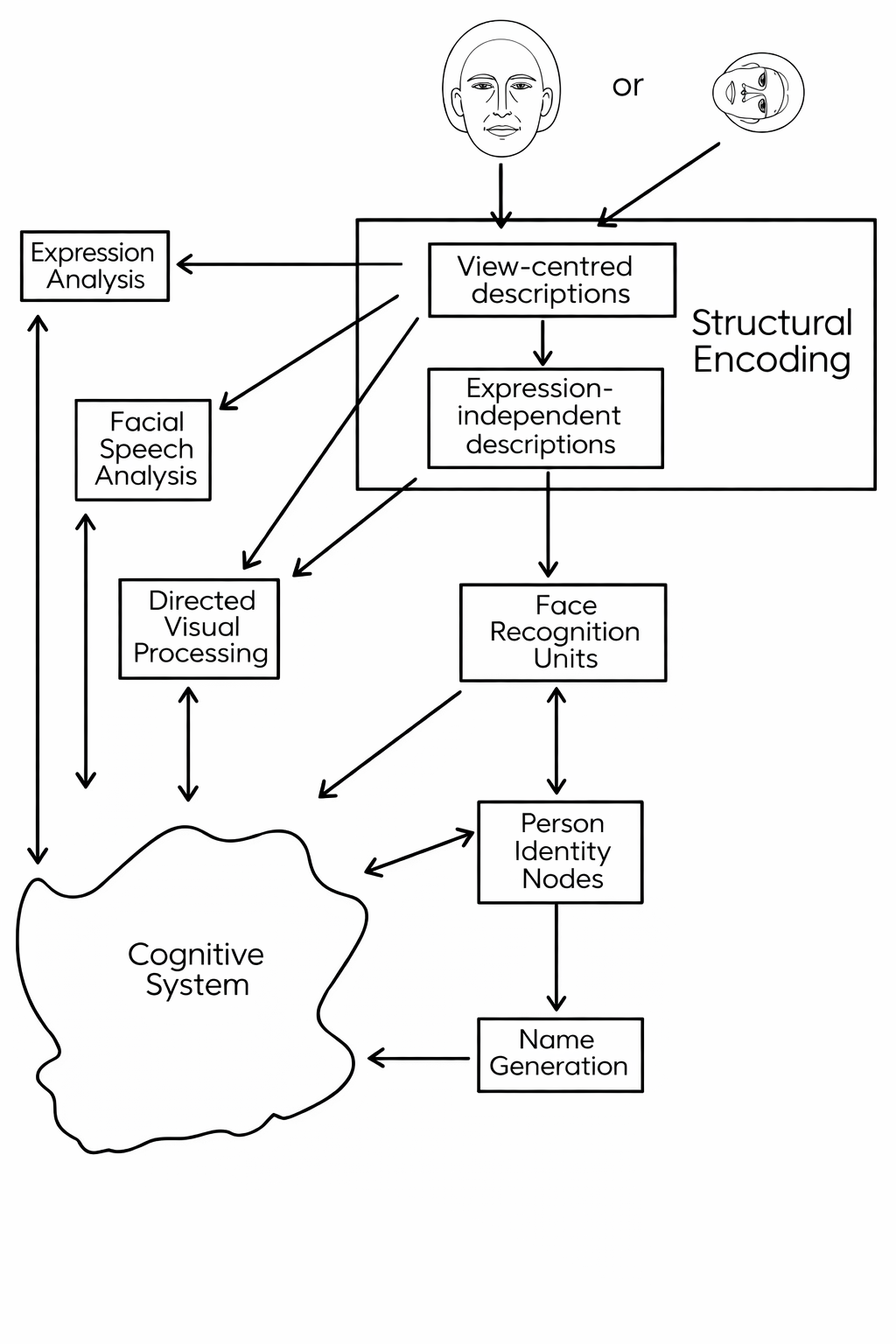
The Bruce and Young model is abstracted from a brain implementation, and a natural candidate for the model hardware is an artificial neural network, to make a potential transition to a neural model. Burton, Bruce, and Johnston formalized parts of the Bruce and Young architecture in an interactive activation model, where face recognition units (FRUs) connect to person identity nodes (PINs) and then to names and semantic information (Burton et al., 1990). The model explains why recognition can be fast for familiar faces and why partial activation can spread across related information. The animated schematic below illustrates the structure of the model, but it is highly simplified, and we recommend you read the original article for more detail.
The Bruce and Young model also predicts a range of dissociations that have been observed in neuropsychological patients and in ordinary cognition. Most of us have experienced the tip-of-the-tongue phenomenon when viewing a familiar face, i.e., we feel they know the person and can retrieve semantic information about them, but the name remains inaccessible. This is exactly what the model predicts when activation reaches the person identity node but fails to propagate reliably to the name node. In other cases, patients with certain types of brain damage can name a person given semantic cues but cannot recognise their face, or can recognise the face but cannot retrieve the name. Each of these patterns maps onto a specific disruption in the model’s architecture, which is one reason the functional account has remained influential.
Neural evidence supports the idea of specialized processing. Prosopagnosia shows that face recognition can be selectively disrupted, and imaging work, as we previously discussed, identifies regions such as the (FFA) that respond strongly to faces (Kanwisher et al., 1997). Other regions, including parts of the occipital cortex and superior temporal sulcus, contribute to encoding identity, gaze, and expression. As indicated above, Haxby and colleagues proposed a distributed system in which multiple regions support different aspects of face information (Haxby et al., 2000). More recent neuroimaging work clarifies the functional division within this network: the occipital face area appears to play a greater role in processing individual features, whereas the FFA is more involved in holistic, configural processing. This distinction aligns with the featural-vs-configural framework discussed earlier and supports the idea that face recognition draws on multiple, functionally specialized stages.
The schematic diagram shown earlier in this chapter (see the neuropsychological evidence section) illustrates Haxby’s proposed distributed network. In brief: the OFA handles early structural encoding; the FFA codes identity; the STS handles changeable aspects such as expression and gaze; and the amygdala links face processing to emotional significance.
9.9.1 Face patches and the neural code for faces
Single-unit recording in macaque monkeys has deepened the neuroimaging account of face processing. Doris Tsao and colleagues have identified a network of discrete regions in the macaque ventral temporal and occipital cortex that they call face patches. These are clusters of neurons that respond selectively and strongly to faces while showing little activation in response to other objects (Tsao et al., 2006). The patches are not a single region but a series of stations along the ventral visual stream, each with a somewhat different tuning profile: some respond most strongly to faces viewed from the front, others to side views, and others to a range of angles. Together they form a processing hierarchy that appears to build up a representation of identity across viewpoints, broadly paralleling the distributed system Haxby and colleagues described with fMRI evidence.
What Tsao’s work has revealed is about how individual neurons within these patches encode a face. The assumption in much of the psychological literature has been that face recognition is fundamentally holistic, as we saw earlier i.e., that faces are processed as irreducible wholes rather than as collections of parts. Tsao’s single-cell recordings challenged a simple version of this idea. She and her colleagues showed that neurons in the face patches do not simply fire in an all-or-nothing way to a face as a gestalt. Instead, each neuron responds to a specific combination of feature contrasts. This might be as a function of the ratio of eye width to face width, or the relative darkness of the eyes compared to the surrounding skin. A given face activates a particular pattern across the population of face-patch neurons, and that pattern is determined by these feature-contrast dimensions. The coding is coordinate-based: each neuron can be thought of as tuned to a point in a multidimensional space defined by these contrasts, and the population response jointly specifies where in that space the face falls.
The clearest demonstration of how much information this code carries came in Chang and Tsao’s (2017) study published in Cell. They recorded from 205 face-selective neurons in one of the face patches while macaques viewed photographs of human faces. Using the population activity pattern (the relative firing rates of all 205 neurons), they were able to reconstruct the face that had been shown, producing images that were recognisably similar to the originals. Each neuron’s contribution to the reconstruction could be traced to its known tuning for specific feature contrasts. This was a concrete demonstration that the neural representation of a face is likely a structured, compositional code.

These findings do not overturn the importance of holistic processing at the behavioural level. The composite-face effect, the inversion effect, and the other phenomena described earlier are real and robust. What Tsao’s work shows is that the neural implementation of face encoding involves a population code that, while it captures configural relationships, does so through the combined action of neurons each tuned to specific feature dimensions. This implies a resolution that exists between pure featural and pure holistic representation. This has implications for how we think about the relationship between psychological and neural explanations of face recognition, and it connects naturally to the representational models discussed in the next section.
9.9.2 Representational models: face space
The functional and neural accounts above describe how face information is processed through a system of stages. A complementary question, partly addressed earlier, is how faces are represented in memory, that is, what form the stored mental image of a face takes. Valentine (1991) proposed an influential geometric account known as the model that we covered briefly earlier in the chapter. In this framework every face is represented as a point in a high-dimensional space, where each dimension corresponds to a feature or measurement extracted during encoding (for example, the relative width of the nose, the distance between the eyebrows, or more abstract configural ratios). The key insight is that an average face (the ‘centroid’ of all the faces in a ‘face space’, or of all the faces a person has encountered) sits at the centre of the space. Individual faces are distributed around the centre, and the distance of any face from the average reflects how distinctive or atypical it is: a very ordinary-looking face clusters near the centre, while an unusual or memorable face lies farther away. This simple geometry allows us to make several predictions. First, it provides a natural explanation for the . A caricature exaggerates the features that distinguish a face from the average, effectively moving the representation farther from the centre of face space. Because recognition depends partly on distinctiveness, a caricature can sometimes be more recognizable than an accurate photograph. A caricature amplifies the signal that distinguishes that individual from everyone else. As we discussed earlier, experimental work has confirmed that well-drawn caricatures are often recognised at least as well as veridical images, and sometimes better, as the model predicts.
Second, the face space model offers an appealing account of the other-group recognition effect. People from a particular environment and learning history encounter faces from their own group far more frequently than faces from other groups. Over time the perceptual system becomes finely tuned to the region of face space densely populated by familiar faces, developing fine-grained sensitivity to distinctions that matter within that region. Faces from a less frequently encountered group occur in a region of space that has been less thoroughly explored, so representational resolution there is coarser. Different individuals cluster more closely together in these sparser regions, making them harder to tell apart. This account predicts that the own-group recognition advantage should decline with greater cross-group contact, although evidence is mixed and effect sizes are modest (Meissner & Brigham, 2001).
O’Toole and colleagues (1994) formalized these ideas within a statistical learning framework. Rather than treating face space as a fixed coordinate system, they modeled the perceptual system as one that continuously adapts its discriminative sensitivity to match the frequency distribution of the faces it encounters. Dimensions along which encountered faces vary a great deal are weighted more heavily and resolved more finely; dimensions that show little variation in everyday experience are compressed. The result is a representational space optimized for the faces the system has actually seen, efficient for familiar populations but less so for unfamiliar ones. This statistical-learning perspective connects Valentine’s geometric intuition to a concrete learning mechanism.
More recently, the geometry of face space has acquired renewed relevance because of deep neural networks. Modern face-recognition systems (discussed in more detail in the section on automated recognition below) learn, from millions of training images, to map each face onto a high-dimensional ‘embedding vector’. That vector is, in effect, the face’s coordinates in a learned space, and the network is trained so that images of the same person land close together while images of different people land far apart. This geometric framing is close to classic face-space ideas and has been used explicitly to link psychological models with machine representations (O’Toole et al., 2018; Schroff et al., 2015).
Developmental findings also matter. As discussed earlier, newborns prefer face-like patterns over scrambled ones, which suggests a bias for face-structured input early in life (M. H. Johnson et al., 1991). That bias is then likely tuned by experience, which is consistent with the other-group recognition effect: recognition is typically better for faces from familiar groups, and it improves with exposure. McKone and colleagues argued, however, that the role of experience in the development of face processing has been overstated. A detailed review of twin studies, data from neonates, and critical-period effects concluded that the mechanisms supporting face individuation appear relatively mature early in life. Face-relevant processing is not simply built up through accumulated practice on faces, but is substantially constrained by biology (McKone et al., 2012). Experience refines and calibrates these mechanisms; it does not build them from scratch. This position does not deny that exposure matters for the other-group recognition effect, but it locates the primary explanation in the tuning of an existing system rather than in the acquisition of a new one.
9.10 Familiarity, memory, and composites
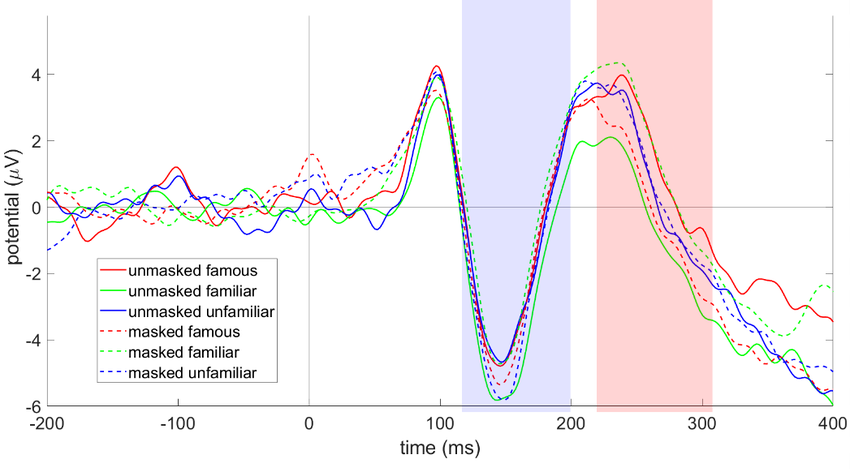
Familiar faces are processed more robustly than unfamiliar faces. With familiarity, recognition is fast and tolerant of changes in lighting, expression, and viewpoint. With unfamiliar faces, recognition is fragile and often tied to the specific image that was seen. This difference helps explain why matching a stranger to a passport photo is harder than recognizing a familiar colleague (Megreya & Burton, 2006; White, Kemp, Jenkins, Matheson, et al., 2014). Several specific differences between familiar and unfamiliar processing have been documented. Internal features are particularly diagnostic for familiar faces, as discussed above, but not for unfamiliar ones. Speed and automaticity differ: seeing a familiar face typically triggers rapid recognition, often accompanied by a feeling of knowing and recall of that person’s name and other semantic information. Brain responses measured by EEG reveal two important components. An early component called the , a negative deflection peaking at around 170 milliseconds, is consistently larger for faces than for other objects and is thought to reflect the structural encoding of face information (Bentin et al., 1996). A later component, the N250, peaking around 250 milliseconds, is modulated by familiarity: it is much larger for familiar faces, reflecting the activation of stored identity-specific representations, whereas unfamiliar faces evoke only generic face-processing activity (Schweinberger et al., 2002).
9.10.1 Within-person variability
Within-person variability makes the familiar-unfamiliar gap particularly stark. A single person can look quite different across images, and unfamiliar observers often treat those images as different people (Jenkins et al., 2011; Megreya & Burton, 2006). A demonstration can make this point vividly: participants are shown a set of photographs and asked to sort them into piles, one pile per unique individual. When the photographs are of strangers, participants commonly create far more piles than actually exist.

They think there are multiple different people, when in fact all the photographs are of the same person taken on different occasions. If the same photographs are of someone familiar to the participants, the task is trivial. Familiarity allows a viewer to ‘see through’ within-person variability; without it, each image is taken at ‘face value’. Identity representations become more stable when learners see broad within-person variation rather than a single canonical photo (Burton et al., 2016).

These differences have a striking practical implication. Recognizing a familiar person who is partially disguised, wearing a hat and a face mask, for example, is still easier than identifying an undisguised stranger from a single brief exposure. The rich representation built up through familiarity provides enough redundancy that partial occlusion does not destroy recognition, whereas the thin representation available for an unfamiliar face is easily overwhelmed by any change in conditions. The COVID-19 pandemic provided a large-scale natural experiment on this theme. When face masks became widespread, studies found substantial drops in face-matching performance for both familiar and unfamiliar faces (Carragher & Hancock, 2020). People adapted by shifting attention toward the eye region, which became the only reliably visible part of the face in many interactions. This rapid adjustment illustrates both the flexibility and the constraints of face processing: the system can partially compensate for occlusion, but the loss of configural information across the lower face still imposes a real cost.
A useful practical consequence of this finding is that averaging multiple images can reduce the problem. Jenkins and colleagues showed that an average of several different photos of a person is often more recognizable than any single photo, because averaging cancels out transient changes such as lighting, expression, and camera angle, and highlights stable facial structure (Jenkins et al., 2011). This idea motivates the use of multiple reference photos or averaged composites in applied settings.

9.10.2 Face composite systems
s (the pictures police create of suspects, often known as ‘Identikits’) are at the intersection of memory and perception. Traditional systems prior to the 2000s built faces feature by feature, selecting a nose from a catalog, then eyes, then hair, for instance, which aligns with a featural approach. However, a collection of individually plausible features does not necessarily produce a recognizable face if the configuration is wrong. Witnesses often find the result hard to describe and unsatisfying without being able to say exactly why. The gestalt is missing: the arrangement that makes a face identifiable has not been captured. We showed an experiment earlier by Kempen and Tredoux that underscores this point.
One reason featural systems struggle is a fundamental mismatch between how witnesses encode an unfamiliar face and how other people later try to recognise it. We know that brief exposure to an unfamiliar face leads witnesses to encode the external features more strongly than the internal: hair, face shape, and head outline. But when someone else subsequently tries to identify that face, whether from a composite or a photograph, they rely primarily on the internal features: the arrangement of the eyes, nose, and mouth. A composite that faithfully captures the external features may therefore look superficially correct while failing to convey the internal-feature information that recognition depends on. This encoding-recognition mismatch is one of the clearest explanations for why feature-based composites so often fail to trigger identification, and it is the problem that holistic systems are designed to address. A detailed review of composite systems, past and present, can be found in (Tredoux, Frowd, et al., 2023)
One holistic face compositional approach shows the witness whole faces and uses an evolutionary algorithm to converge on a likeness through iterative selection. The witness picks the faces that look closest to the target from an array; the system generates a new set of faces by blending elements of the chosen ones: not as simple cut-and-paste features, but by blending in the underlying face model. Then the witness selects again, and so on. A system called EvoFIT, developed by Frowd and colleagues, works along these lines. At the University of Cape Town, a system called ID uses a statistical model of faces based on principal component analysis to generate realistic-looking synthetic faces (Tredoux et al., 2006). Instead of manually selecting a nose shape from a menu, the witness navigates “face space” by choosing from computer-generated variants, effectively steering toward the correct appearance by holistic similarity judgments.
Click here to access a web version of the ID software for demonstration.
Navigate “face space” by selecting faces similar to a target, then let the system evolve a composite based on your choices.
Holistic systems tend to produce composites that are more readily recognised by others than those assembled feature by feature. Nonetheless, even the best composites are often only a rough approximation of the actual face. Frowd and colleagues developed what they call the ‘gold standard’ for evaluating composites: witnesses view a target face, construct a composite after a realistic delay, and the composite is then shown to people who are familiar with the target to see whether they can name the person. When the delay between viewing and construction is short e.g. under an hour correct naming rates for the better computerised systems reaches around 15 to 20 per cent, and perhaps even higher. When the delay is extended to two days, as is more typical of real investigations, correct naming drops to around 5 per cent or less for most systems (Frowd et al., 2005). Under realistic conditions, composites are correctly identified only a small fraction of the time and are best treated as investigative leads rather than evidence of identity. Frowd and colleagues have documented these naming rates across multiple studies and system types, with holistic systems consistently outperforming feature-based alternatives under realistic delays (Frowd et al., 2005, 2007).
Several refinements have improved the recognizability of finished composites. When more than one witness is available, combining their independently constructed composites into an averaged (“morphed”) image often produces better results than any single composite: uncorrelated errors in the individual composites tend to cancel out in the average, leaving a face that is more recognizable. This effect was demonstrated by Bruce and colleagues (2002). When only one composite is available, a dynamic caricature technique has proved effective: the composite is animated so that it smoothly exaggerates and then de-emphasises its distinctive features, and different frames in the sequence can each serve as a cue to identity. You will find this feature available in the ID software programme that we gave you the link to earlier.
A concern sometimes raised in legal proceedings and media coverage is whether constructing or viewing a composite damages the witness’s original memory of the perpetrator. Verbal description can interfere with later visual identification in some tasks (Schooler & Engstler-Schooler, 1990). Evidence on composite construction effects is mixed and depends on procedure and delay (Sporer et al., 2020). A research synthesis and meta-analysis by Tredoux and colleagues (2021), covering 23 studies and over 2,200 participants, found no significant negative effects of composite construction on subsequent lineup identification. Some weak evidence suggested that composite construction may even reduce incorrect identifications in target-present lineups, though effect sizes were small. The meta-analytic conclusion is that warnings about memory contamination from composites are not well supported by the empirical literature.
The practical lesson mirrors the theoretical one: focusing on individual features in isolation is not enough, the configuration must be right. Modern composite techniques attempt to respect the holistic nature of face memory. Increasingly, law enforcement supplements composites with clear surveillance images or facial recognition software when available. Some authorities now prefer releasing surveillance footage directly to the public, which can yield tips that are more reliable than a composite sketch. Another option is using a skilled artist who sketches while the witness provides a holistic description; a talented artist can sometimes capture a likeness by intuitively working with configural cues that pure feature selection might miss, although there is little direct evidence to test this supposition.
9.11 Face matching in applied settings
Face matching is the task of deciding whether two images show the same person. This is common in passport control, security screening, and forensic work. The task looks straightforward because both images are visible, but performance is often surprisingly poor with unfamiliar faces. In one study, supermarket cashiers accepted a large proportion of fraudulent credit cards when the photo did not match the customer (Kemp et al., 1997). Laboratory work shows error rates on unfamiliar face matching are typically around 20-30 per cent, even under good photographic conditions. In one benchmark test, professional staff at a passport issuance office still made around 10 per cent errors in identity verification, and untrained participants often exceeded 20 per cent on the same task (White, Kemp, Jenkins, Matheson, et al., 2014). These rates are high: in security contexts even a one per cent error rate can be consequential.
Target
Array
Try the face matching task. You will study a target face and then choose the matching face from a six-item array. The stimuli are simplified cartoon faces rather than photographs, so the exercise is best treated as an illustration of the attentional demands of unfamiliar-face matching rather than as a realistic measure of forensic performance.
Several factors contribute to the difficulty. Within-person appearance variability, discussed above, means that two images of the same person taken on different occasions can look as dissimilar as images of two different people. The other-group recognition effect is also relevant: people are generally less accurate at matching faces from a group other than their own, which adds difficulty in international security settings. And in many real-world contexts, operators receive no feedback on whether their decisions were correct. A security guard may never find out if the ID they approved belonged to an impostor, or if the person they flagged was innocent. Without feedback, performance may not improve over time, and operators may remain overconfident in their flawed matching ability.
Psychologically, unfamiliar face matching is more akin to a demanding perceptual comparison task than to the phenomenologically effortless recognition we experience for friends and colleagues. It requires careful scrutiny and is prone to lapses, especially when many comparisons must be made in a short time, as is the case for border agents checking passports during a busy period or security personnel scanning a crowd. The mismatch between the perceived simplicity of the task (“just compare the two faces”) and the actual difficulty means that errors are often not noticed, either by the operator or by the organization. This gap between confidence and accuracy is a recurring theme in face-matching research.
Recent intervention work shows that design choices can improve performance. Redesigned photo-ID formats, variable image sets, and explicit feature comparison instructions each improve unfamiliar-face matching in controlled tests (Megreya & Bindemann, 2018; Menon et al., 2015; White, Burton, et al., 2014).
9.11.1 Real-world consequences
Real-world cases illustrate the consequences of matching errors. In January 2020, Robert Williams in Detroit was wrongfully arrested after a facial-recognition-generated lead, and the case is now widely cited as a cautionary example of false-positive risk when automated matches are not independently validated (American Civil Liberties Union, 2020).
9.11.2 Anthropometric face comparison
One widely used forensic technique for comparing a face in CCTV footage to a photograph of a known suspect is . The examiner identifies a set of anatomical landmarks on both images, e.g., the inner and outer corners of the eyes, the tip and base of the nose, the corners of the mouth, and several others, and measures the pixel distances between them. Because the two images will almost certainly have been captured at different distances from the camera, raw distances cannot be compared directly. Instead the examiner might compute ratios between pairs of measurements: for example, the ratio of the inter-pupillary distance to the length of the nose, or the ratio of mouth width to face width. If the two images show the same person, the argument goes, these ratios should be similar regardless of scale. The examiner compares the ratio sets and reports whether they are “consistent with” or “inconsistent with” the two faces belonging to the same individual. The technique has been used extensively by police forces in the United Kingdom and elsewhere, and forensic examiners have presented anthropometric evidence in court in a number of cases. Its appeal is understandable: it promises to reduce face comparison to an objective, measurable procedure.
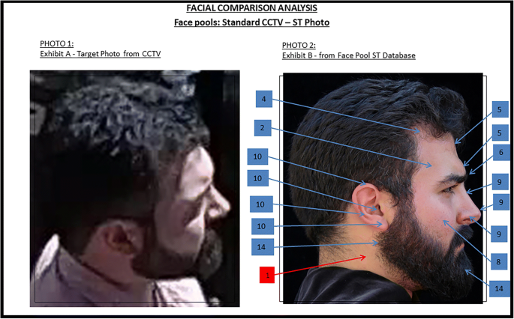
However, the scientific foundations of the method are weaker than its forensic prevalence might suggest, and several sources of error compound one another. The first and most serious is perspective distortion. A face viewed even a few degrees off the frontal plane shows foreshortening on the far side: distances on that side of the face appear compressed relative to the near side. Most CCTV images are not frontal, and the yaw angle is often unknown, which means that measured ratios will differ from their true frontal values in ways that depend on the viewing geometry. There is no standard correction for this, and the distortion can be large enough to push ratios outside the tolerance that an examiner would regard as a match, or, conversely, to bring the ratios of two different people into apparent agreement.


Perspective distortion in face photographs. Both panels show that measured facial ratios vary systematically with imaging conditions, undermining anthropometric comparison when the two images were taken under different conditions.

Landmark placement adds a second layer of uncertainty. Terms such as “corner of the eye” or “tip of the nose” refer to regions rather than single points, and different examiners will place landmarks in slightly different positions. Inter-examiner variability in landmark placement can alter computed ratios by amounts that are forensically significant. Facial expression introduces a third problem: a neutral expression and a smile produce substantially different mouth-to-face ratios, and many other landmarks shift with expression. Age-related changes in facial structure add yet another confound when the two images were taken years apart.
Beyond these measurement problems there is a more fundamental issue. Facial proportions are not sufficiently distinctive to reliably tell individuals apart. Unlike fingerprints, the set of ratios that an anthropometric comparison typically uses, usually between ten and twenty, does not carry enough discriminating power to distinguish faces that are merely similar. Two different people with broadly similar facial structure can produce ratio sets that fall within an examiner’s tolerance for a match. A finding of consistency therefore does not provide strong evidence of identity, yet in practice such findings have sometimes been treated as highly probative in court proceedings (Bacci et al., 2021; Davis & Valentine, 2009).
A South African case often discussed in this context is that of Zwelethu Mthethwa, in which comparison between CCTV video frames and a photograph of the accused became a major evidential issue. Critics argued that the image quality was too poor and the viewing conditions too unfavourable to support confident identification from anthropometric ratios alone (Bacci et al., 2021).
For a broad overview of face matching in applied settings, see White et al. (2014) and Davis and Valentine (2009).
The technique has attracted increasing scrutiny from both the scientific community and forensic regulators. The UK Forensic Science Regulator’s codes emphasise that methods used in forensic casework should be validated and accompanied by explicit statements of limitations and uncertainty (Forensic Science Regulator, 2025). The U.S. National Academy of Sciences similarly highlighted the broader problem of forensic disciplines that had not undergone rigorous empirical validation with known error rates (National Research Council, 2009). Courts have responded with varying degrees of scepticism, and the long-term trajectory is toward greater demands for validated error-rate data before such evidence is given greater weight.
The lesson connects directly to the themes of this chapter. Anthropometric comparison is, in essence, a manual and purely featural approach: it reduces a face to a small set of measured distances and compares those distances across images. Everything the research on configural and holistic processing tells us predicts that such an approach will be error-prone, because it discards the relational structure that is most informative for face identity. Automated systems that learn high-dimensional representations from data do substantially better. This is not because they are infallible, but because they capture far more of the spatial relationships among features than a handful of manually measured ratios. And even human examiners using holistic judgment, imperfectly as they do so, may outperform a purely metric approach, because holistic processing integrates information across the face in ways that ratio-based comparison cannot replicate.
9.11.3 Face comparison and evidence reporting
Face comparison is broader than binary matching. Forensic comparisons often involve low-quality images, viewpoint mismatch, and explicit uncertainty judgments. Evidence from forensic examiner studies shows that expertise can improve accuracy, but error is not eliminated (Phillips et al., 2018). CCTV-to-suspect comparisons are especially sensitive to image quality, compression artifacts, and pose mismatch (Davis & Valentine, 2009). Reports should document image limitations and the uncertainty of conclusions.
South African work has contributed to mapping this landscape. Bacci and colleagues (2021) surveyed the state of forensic facial comparison in South Africa, documenting current practice, training, and the gap between practitioner confidence and empirically validated performance. Their survey found that practitioners often lack standardised training and that the field operates largely without published error-rate data, a problem highlighted internationally by the National Academy of Sciences (2009) as common across many forensic disciplines.
9.11.4 Strategies for improvement
Several approaches improve performance. Seeing multiple reference images helps observers generalise across within-person variability. Averaging several images into a single composite can highlight stable structure by cancelling out image-specific noise. Researchers have demonstrated that an averaged face generated from multiple photographs is often more recognizable than any single image (Jenkins et al., 2011). The idea has begun to influence forensic practice: creating an average face from multiple CCTV frames of a suspect can yield a clearer representation than a single blurry frame. Some passport and driver’s licence issuers are considering capturing short video clips rather than single photographs, so that an average or representative frame can be extracted for verification (Burton et al., 2016).
Training and feedback can also help, though the gains are typically modest. Security personnel sometimes undergo specialized training in which they practice on known sets of photo comparisons and learn about common pitfalls such as the other-group recognition effect or the influence of superficial cues like hairstyle. Where feedback is feasible - for example, a security organization reviewing decisions and informing staff about errors - performance can improve over time (White, Kemp, Jenkins, & Burton, 2014).
s are consistently better than average at face matching and are now used in some policing contexts (Bobak et al., 2016). UK policing reports describe targeted recruitment and deployment of super-recognisers for CCTV and suspect identification tasks (Robertson et al., 2016). Standardized tests can be used to screen for this ability. A large-scale comparison by Phillips and colleagues found that the best super-recognisers performed comparably to state-of-the-art face recognition algorithms, and in some conditions outperformed them (Phillips et al., 2018). The most reliable improvements come from combining human and machine decisions: algorithms can narrow a search and humans can make final judgments where contextual or legal considerations matter. An algorithm might flag potential matches from hours of footage, and human investigators review the candidates to make the final identification. The machine handles scale and speed; the human handles context and accountability. Such hybrid systems leverage the strengths of each and are increasingly being implemented. These strategies reduce error, but they do not eliminate it, which is why face matches should be supported by additional evidence when decisions are high-stakes.
9.12 Automated face recognition systems
Note: this section is of higher complexity; you can omit it safely if you find it hard-going.
Automated systems now perform face recognition at scale. The pipeline usually includes detection (finding the face in the image), encoding (turning it into a feature vector), and matching (comparing that vector to a database). Each stage has evolved considerably over the past two decades.
The r4lineups package includes a face similarity computation tool. You can try it at the link below. Given two face images, the tool computes a similarity score based on geometric and textural features.
9.12.1 Applications
The applications of automated face recognition are broad. In security and law enforcement, systems identify known criminals or suspects in surveillance footage, match faces against watchlists at airports and border checkpoints, and verify passports at airport e-gates. Personal devices may use face authentication to unlock phones and laptops. In forensics, systems search databases of mugshots or driver’s license photos to find a match to a crime-scene image, and scan public camera feeds for missing persons. Commercial applications include tagging and organizing photographs by person in cloud photo libraries, auto-tagging features on social media, and identifying VIP customers or known shoplifters in retail settings. Some workplaces and schools use face recognition for attendance and access control; there have even been reports of a public restroom in China using face recognition to dispense toilet paper to prevent theft (a widely reported anecdote without peer-reviewed documentation, included here as an illustration of the technology’s reach). These uses range from convenient to controversial. Unlike fingerprint or iris scans, faces can be captured at a distance without a person’s knowledge or consent, enabling covert mass identification. This has led to public debate and, in some regions, regulations limiting use.
9.12.2 Detection and encoding
Face detection algorithms locate and isolate face regions from photographs or video frames. Modern detectors work reliably across a range of poses and lighting conditions. Encoding - converting a detected face into a numerical representation - is where the technology has changed most dramatically.
Earlier systems used a technique called principal component analysis (PCA) to derive what are known as . In this approach, a large set of face images is analysed to find the principal components - eigenvectors - that account for most of the variance across those images. These components look like ghostly, abstract faces. Any new face image is then represented as a weighted combination of these eigenfaces, and the resulting set of coefficients serves as a numerical fingerprint. Two images of the same person should, in theory, yield similar coefficient sets.

Current systems rely on deep convolutional neural networks that learn embeddings, which are feature vectors produced by a network trained on millions of face images. The network’s parameters are optimized so that two photographs of the same person produce very similar vectors, while photographs of different people produce vectors that are far apart. Conceptually, both and deep-network approaches map faces into a high-dimensional face space in which distance corresponds to similarity. The deep-network embeddings are much more discriminating than the older linear methods.
9.12.3 Matching and performance
Once faces are encoded as feature vectors, comparing them is straightforward. For verification - “Is this person X?” - the system measures the distance between the new face’s vector and the stored vector for X, and declares a match if the distance falls below a threshold. For identification - “Who is this person?” - the system finds the closest vector in the database. Large-scale systems must search efficiently through millions of vectors, a task aided by indexing schemes and specialized hardware.
Modern algorithms, especially deep-network systems, have achieved impressive accuracy on standardized benchmarks. Google’s FaceNet reported 99.63 per cent accuracy on the LFW benchmark in 2015, exceeding the reported human baseline on that test (Schroff et al., 2015). Performance can be high in controlled conditions but drops with low-quality images, extreme viewing angles, or large changes in appearance over time.
9.12.4 Bias and the base rate problem
Algorithms can inherit bias from the data they are trained on. If the training set is demographically skewed, the system will be less accurate for underrepresented groups. Large-scale evaluations by NIST (the National Institute of Standards and Technology, the US federal agency responsible for technology measurement standards) documented demographic differences in false-match and false-miss rates across face-recognition systems (Grother et al., 2019). These findings mirror the other-group recognition effect seen in human recognition: both humans and algorithms struggle most with faces from groups that are under-represented in their experience or training data.
In surveillance settings, the base rate problem creates a further challenge. When the target is rare, even a very low false positive rate can produce many false alarms. Consider an airport scenario: 200,000 passengers pass through in a day and the system is searching for one individual on a watchlist. If the false positive rate is 0.001 per cent - one in 100,000 non-target faces triggers an alarm - then about two passengers will be falsely flagged on a typical day. Whether an alarm is more likely to be correct than false then depends on the system’s hit rate as well as on that false positive rate. If the target is not present, every alarm is a false alarm. Security officers could therefore be chasing numerous false leads, and if this happens repeatedly they may begin to distrust or ignore the system. The base rate problem is not a flaw of the algorithm; it is a statistical reality when searching for rare targets.
9.12.5 Spoofing, transparency, and ethics
‘Spoofing’, that is showing the system a high-quality photograph or wearing a realistic mask, is a concern. Advanced systems now use liveness detection, requiring a blink or head movement or using depth sensors to confirm a three-dimensional face, to guard against this. Transparency is another issue: deep-learning systems are often black boxes that make correct predictions but, when they err, it can be difficult to understand why (Goodfellow et al., 2016).
From an ethical and legal standpoint, the growing capabilities of face recognition have prompted significant debate. In May 2019, San Francisco passed an ordinance prohibiting most municipal uses of facial recognition technology (City and County of San Francisco, 2019). On the other hand, the technology has had successes, identifying victims of human trafficking by matching images to missing persons databases for instance, or catching imposters using fraudulent passports that even trained officers missed.
A sensible approach might be hybrid. Machines handle scale and speed; humans handle context and accountability. In practice this means automated candidate lists followed by human review, rather than fully automated decisions.
The trajectory of face recognition technology suggests it will become even more accurate and ubiquitous. Algorithms continue to improve, and new techniques such as training on synthetic faces generated by neural networks, or incorporating video sequences to leverage motion patterns and temporal consistency are already in use. However, as this chapter has shown, there are conceptual hurdles such as base rates, demographic bias, and the black-box problem that pure algorithmic improvements cannot solve alone.
9.12.6 Developmental trajectory
The neural and perceptual systems that support face recognition are not fully formed at birth; they are refined through experience over childhood and adolescence. Infants show the newborn preference for face-like patterns described above, but their ability to discriminate among individual faces develops later. Research has shown that young infants - around three months of age - can discriminate faces across all racial groups, but by nine months they have begun to specialize for faces from their own group, an early manifestation of the other-group recognition effect (Kelly et al., 2007; Pascalis et al., 2002). This pattern is known as : broad initial sensitivity becomes tuned by experience, and discrimination of non-native face categories can decline across the first year. Cross-group experience is particularly important during this window, and children who grow up in diverse environments tend to show smaller other-group recognition effects than those exposed primarily to faces from one group. This sensitivity to early experience explains why the other-group recognition effect, once established, can be difficult to reverse in adulthood without deliberate training or sustained exposure.
Face recognition continues to develop well into adolescence and even into early adulthood. Research has documented a period of reorganization during puberty, with adolescents sometimes showing temporary disruptions in face recognition before emerging with more mature processing. Importantly, face learning ability does not peak at the same time as most other cognitive skills. Germine, Duchaine, and Nakayama found that the ability to learn new faces continues to improve and does not peak until after age thirty - later than many other perceptual and cognitive abilities (Germine et al., 2011). This has practical implications: it means that younger operators or eyewitnesses are not necessarily at their best, and that experience with faces continues to accumulate well beyond adolescence. At the other end of the lifespan, older adults show selective deficits in processing configural information, though recognition of highly familiar faces may be relatively preserved. These patterns across the lifespan underscore that face recognition is not a fixed capacity but a system that is continuously shaped by experience and biological change.
9.12.7 Putting it together
Face recognition occupies a distinctive place in cognitive psychology because it connects laboratory research to questions of immediate practical importance. The basic science, that is how faces are encoded, represented, and remembered, has direct implications for eyewitness testimony, identity verification, forensic comparison, and automated surveillance. This chapter has traced that connection through several levels of analysis.
At the perceptual level, faces are processed holistically and relationally. The inversion effect, the Thatcher illusion, and the chimeric face paradigm all demonstrate that recognition depends on spatial relationships among features, not just on the features themselves. Face space provides a geometric framework that unifies s, distinctiveness advantages, and the other-group recognition effect within a single account: faces are encoded relative to an average, and deviation from that average is what makes a face memorable and distinctive.
At the neural level, the picture is one of a distributed but specialised system. The OFA handles early structural encoding; the FFA represents identity; the STS processes changeable aspects such as expression and gaze. Single-unit recording in macaques has revealed that this holistic output is achieved through a coordinate-based population code, with individual neurons tuned to specific feature contrasts. The human developmental trajectory — from the neonate’s preference for face-like patterns through the narrowing of sensitivity in the first year and into the continuing maturation of face learning well past adolescence — reflects both biological predisposition and experiential tuning.
At the applied level, several findings stand out. Recognition of unfamiliar faces is fragile in ways that recognition of familiar faces is not: performance on passport verification and CCTV face matching is poor even for trained professionals, and designing better procedures requires understanding why. Face composites are useful investigative tools but have real limits; the shift to holistic systems has improved naming rates, and the meta-analytic evidence does not support concern about memory contamination. Forensic facial comparison using anthropometric ratios is widespread but poorly validated; its purely featural logic runs counter to what the science of face processing tells us about where identity information lies. Automated systems outperform manual ratio analysis, but they inherit biases from training data and create new ethical challenges around covert surveillance, accountability, and the statistical consequences of rare-target identification.
The unifying thread is that face processing is simultaneously a perceptual achievement, a memory system, a developmental trajectory, and a socially embedded skill. What makes it easy to recognise a friend across a crowded room is also what makes it hard to verify a stranger’s passport photograph, what explains the own-group recognition advantage, and what determines both the strengths and the failure modes of artificial face recognition systems. Progress in any of these domains is more likely when it draws on the full range of evidence, from infant preferences and single neurons to courtroom cases and mass surveillance policy, rather than treating each as a separate problem.